








This article discusses a C++ scheme for accessing hardware registers in an optimal way.
Exploiting C++'s features for efficient and safe hardware register access.
This article originally appeared in C/C++ Users Journal, and is reproduced by kind permission.
Embedded programmers traditionally use C as their language of choice. And why not? It's lean and efficient, and allows you to get as close to the metal as you want. Of course C++, used properly, provides the same level of efficiency as the best C code. But we can also leverage powerful C++ features to write cleaner, safer, more elegant low-level code. This article demonstrates this by discussing a C++ scheme for accessing hardware registers in an optimal way.
Demystifying Register Access
Embedded programming is often seen as black magic by those not initiated into the cult. It does require a slightly different mindset; a resource constrained environment needs small, lean code to get the most out of a slow processor or a tight memory limit. To understand the approach I present we'll first review the mechanisms for register access in such an environment. Hardcore embedded developers can probably skip ahead; otherwise here's the view from 10,000 feet.
Most embedded code needs to service hardware directly. This seemingly magical act is not that hard at all. Some kinds of register need a little more fiddling to get at than others, but you certainly don't need an eye-of-newt or any voodoo dances. The exact mechanism depends on how your circuit board is wired up. The common types of register access are:
-
Memory mapped I/O The hardware allows us to communicate with a device using the same instructions as memory access. The device is wired up to live at memory address n; register 1 is mapped at address n, register 2 is at n+1, register 3 at n+2, and so on.
-
Port mapped I/O Certain devices present pages of registers that you have to map into memory by selecting the correct device 'port'. You might use specific input/output CPU instructions to talk to these devices, although more often the port and its selector are mapped directly into the memory address space.
-
Bus separated It's harder to control devices connected over a non-memory mapped bus. I 2 C and I2S are common peripheral connection buses. In this scenario you must either talk to a dedicated I 2 C control chip (whose registers are memory mapped), telling it what to send to the device, or you manipulate I 2 C control lines yourself using GPIO [ 1 ] ports on some other memory mapped device.
Each device has a data sheet that describes (amongst other things) the registers it contains, what they do, and how to use them. Registers are a fixed number of bits wide - this is usually determined by the type of device you are using. This is an important fact to know: some devices will lock up if you write the wrong width data to them. With fixed width registers, many devices cram several bits of functionality into one register as a 'bitset'. The data sheet would describe this diagrammatically in a similar manner to Figure 1.
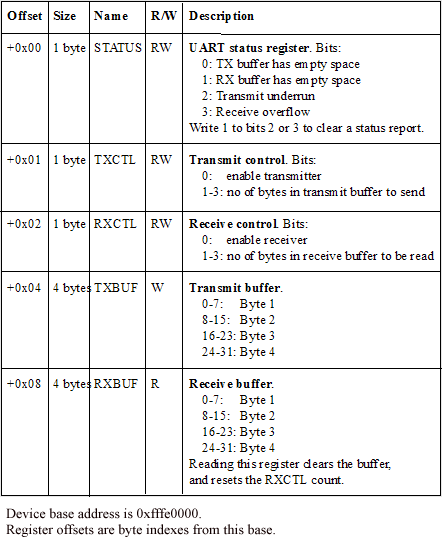
Figure 1. Registers in a sample UART line driver device
So what does hardware access code look like? Using the simple example of a fictional UART line driver device presented in Figure 1, the traditional C-style schemes are:
-
Direct memory pointer access . It's not unheard of to see register access code like Listing 1, but we all know that the perpetrators of this kind of monstrosity should be taken outside and slowly tortured. It's neither readable nor maintainable.
Pointer usage is usually made bearable by defining a macro name for each register location. There are two distinct macro flavours. The first macro style defines bare memory addresses (as in Listing 2). The only real advantage of this is that you can share the definition with assembly code parsed using the C preprocessor. As you can see, its use is long-winded in normal C code, and prone to error - you have to get the cast right each time. The alternative, in Listing 3, is to include the cast in the macro itself; far nicer in C. Unless there's a lot of assembly code this latter approach is preferable.
We use macros because they have no overhead in terms of code speed or size. The alternative, creating a physical pointer variable to describe each register location, would have a negative impact on both code performance and executable size. However, macros are gross and C++ programmers are already smelling a rat here. There are plenty of problems with this fragile scheme. It's programming at a very low level, and the code's real intent is not clear- it's hard to spot all register accesses as you browse a function.
-
Deferred assignment is a cute technique that allows you to write code like Listing 4, defining the register location values at link time. This is not commonly used; it's cumbersome when you have a number of large devices, and not all compilers provide this functionality. It requires you to run a flat (non virtual) memory model.
-
Use a struct to describe the register layout in memory, as in Listing 5. There's a lot to be said for this approach - it's logical and reasonably readable. However, it has one big drawback: it is not standards-compliant. Neither the C nor C++ standards specify how the contents of a struct are laid out in memory. You are guaranteed an exact ordering, but you don't know how the compiler will pad out non-aligned items. Indeed, some compilers have proprietary extensions or switches to determine this behaviour. Your code might work fine with one compiler and produce startling results on another.
-
Create a function to access the registers and hide all the gross stuff in there. On less speedy devices this might be prohibitively slow, but for most applications it is perfectly adequate, especially for registers that are accessed infrequently. For port mapped registers this makes a lot of sense; their access requires complex logic, and writing all this out longhand is tortuous and easy to get wrong.
It remains for us see how to manipulate registers containing a bitset. Conventionally we write such code by hand, something like Listing 6. This is a sure-fire way to cause yourself untold grief, tracking down odd device behaviour. It's very easy to manipulate the wrong bit and get very confusing results.
#define UART_RX_BYTES 0x0e
uint32_t uart_read()
{
while ((*UART_RXCTL & UART_RX_BYTES) == 0)
// manipulate here
{
; // wait
}
return *UART_RXBUF;
}
Listing 6
Does all this sound messy and error prone? Welcome to the world of hardware devices. And this is just addressing the device: what you write into the registers is your own business, and part of what makes device control so painful. Data sheets are often ambiguous or miss essential information, and devices magically require registers to be accessed in a certain order. There will never be a silver bullet and you'll always have to wrestle these demons. All I can promise is to make the fight less biased to the hardware's side.
A More Modern Solution
So having seen the state of the art, at least in the C world, how can we move into the 21st century? Being good C++ citizens we'd ideally avoid all that nasty preprocessor use and find a way to insulate us from our own stupidity. By the end of the article you'll have seen how to do all this and more. The real beauty of the following scheme is its simplicity. It's a solid, proven approach and has been used for the last five years in production code deployed in tens of thousands of units across three continents. Here's the recipe…
Step one is to junk the whole preprocessor macro scheme, and define the device's registers in a good old-fashioned enumeration. For the moment we'll call this enumeration Register. We immediately lose the ability to share definitions with assembly code, but this was never a compelling benefit anyway. The enumeration values are specified as offsets from the device's base memory address. This is how they are presented in the device's datasheet, which makes it easier to check for validity. Some data sheets show byte offsets from the base address (so 32-bit register offsets increment by 4 each time), whilst others show 'word' offsets (so 32-bit register offsets increment by 1 each time). For simplicity, we'll write the enumeration values however the datasheet works.
The next step is to write an inline regAddress function that converts the enumeration to a physical address. This function will be a very simple calculation determined by the type of offset in the enumeration. For the moment we'll presume that the device is memory mapped at a known fixed address. This implies the simplest MMU configuration, with no virtual memory address space in operation. This mode of operation is not at all uncommon in embedded devices. Putting all this together results in Listing 7.
static const unsigned int baseAddress =
0xfffe0000;
enum Registers
{
STATUS = 0x00, // UART status register
TXCTL = 0x01, // Transmit control
RXCTL = 0x02, // Receive control
. and so on ...
};
inline volatile uint8_t *regAddress
(Registers reg)
{
return reinterpret_cast<volatile
uint8_t*>(baseAddress + reg);
}
Listing 7
The missing part of this jigsaw puzzle is the method of reading/writing registers. We'll do this with two simple inline functions, regRead and regWrite , shown in Listing 8. Being inline, all these functions can work together to make neat, readable register access code with no runtime overhead whatsoever. That's mildly impressive, but we can do so much more.
inline uint8_t regRead(Registers reg)
{
return *regAddress(reg);
}
inline void regWrite
(Registers reg, uint8_t value)
{
*regAddress(reg) = value;
}
Listing 8
Different Width Registers
Up until this point you could achieve the same effect in C with judicious use of macros. We've not yet written anything groundbreaking. But if our device has some 8-bit registers and some 32-bit registers we can describe each set in a different enumeration. Let's imaginatively call these Register8 and Register32. Thanks to C++'s strong typing of enums, now we can overload the register access functions, as demonstrated in Listing 9.
// New enums for each register width
enum Registers8
{
STATUS = 0x00, // UART status register
... and so on ...
};
enum Registers32
{
TXBUF = 0x04, // Transmit buffer
... and so on ...
};
// Two overloads of regAddress
inline volatile uint8_t *regAddress
(Registers8 reg)
{
return reinterpret_cast<volatile uint8_t*>
(baseAddress + reg);
}
inline volatile uint32_t *regAddress
(Registers32 reg)
{
return reinterpret_cast<volatile uint32_t*>
(baseAddress + reg);
}
// Two overloads of regRead
inline uint8_t regRead(Registers8 reg)
{
return *regAddress(reg);
}
inline uint32_t regRead(Registers32 reg)
{
return *regAddress(reg);
}
..similarly for regWrite ...
Listing 9
Now things are getting interesting: we still need only type regRead to access a register, but the compiler will automatically ensure that we get the correct width register access. The only way to do this in C is manually, by defining multiple read/write macros and selecting the correct one by hand each time. This overloading shifts the onus of knowing which registers require 8 or 32-bit writes from the programmer using the device to the compiler. A whole class of error silently disappears. Marvellous!
Extending to Multiple Devices
An embedded system is composed of many separate devices, each performing their allotted task. Perhaps you have a UART for control, a network chip for communication, a sound device for audible warnings, and more. We need to define multiple register sets with different base addresses and associated bitset definitions. Some large devices (like super I/O chips) consist of several subsystems that work independently of one another; we'd also like to keep the register definitions for these parts distinct.
The classic C technique is to augment each block of register definition names with a logical prefix. For example, we'd define the UART transmit buffer like this:
#define MYDEVICE_UART_TXBUF
((volatile uint32_t *)0xffe0004)
C++ provides an ideal replacement mechanism that solves more than just this aesthetic blight. We can group register definitions within namespaces. The nest of underscored names is replaced by :: qualifications - a better, syntactic indication of relationship. Because the overload rules honour namespaces, we can never write a register value to the wrong device block: it's a syntactic error. This is a simple trick, but it makes the scheme incredibly usable and powerful.
Proof of Efficiency
Perhaps you think that this is an obviously a good solution, or you're just presuming that I'm right. However, a lot of old-school embedded programmers are not so easily persuaded. When I introduced this scheme in one company I met a lot of resistance from C programmers who could just not believe that the inline functions resulted in code as efficient as the proven macro technique.
| Register access method | Results (object file size in bytes) | |
|---|---|---|
| Unoptimised | Optimised | |
| C++ inline function scheme | 1087 | 551 |
| C++ using #defines | 604 | 551 |
| C using #defines | 612 | 588 |
The only way to persuade them was with hard data - I compiled equivalent code using both techniques for the target platform (gcc targeting a MIPS device). The results are listed in the table below. An inspection of the machine code generated for each kind of register access showed that the code was identical. You can't argue with that! It's particularly interesting to note that the #define method in C is slightly larger than the C++ equivalent. This is a peculiarity of the gcc toolchain - the assembly listing for the two main functions is identical: the difference in file size is down to the glue around the function code.
Namespacing also allows us to write more readable code with a judicious sprinkling of using declarations inside device setup functions. Koenig lookup combats excess verbiage in our code. If we have register sets in two namespaces DevA and DevB , we needn't quality a regRead call, just the register name. The compiler can infer the correct regRead overload in the correct namespace from its parameter type. You only have to write:
uint32_t value = regRead(DevA::MYREGISTER);
// note: not DevA::regRead(...)
Variable Base Addresses
Not every operating environment is as simplistic as we've seen so far. If a virtual memory system is in use then you can't directly access the physical memory mapped locations - they are hidden behind the virtual address space. Fortunately, every OS provides a mechanism to map known physical memory locations into the current process' virtual address space.
A simple modification allows us to accommodate this memory indirection. We must change the baseAddress variable from a simple static const pointer to a real variable. The header file defines it as extern, and before any register accesses you must arrange to define and assign it in your code. The definition of baseAddress will be necessarily system specific.
Other Usage
Here are a few extra considerations for the use of this register access scheme:
-
Just as we use namespaces to separate device definitions, it's a good idea to choose header file names that reflect the logical device relationships. It's best to nest the headers in directories corresponding to the namespace names.
-
A real bonus of this register access scheme is that you can easily substitute alternative regRead/regWrite implementations. It's easy to extend your code to add register access logging, for example. I have used this technique to successfully debug hardware problems. Alternatively, you can set a breakpoint on register access, or introduce a brief delay after each write (this quick change shows whether a device needs a pause to action each register assignment).
-
It's important to understand that this scheme leads to larger unoptimised builds. Although it's remarkably rare to not optimise your code, without optimisation inline functions are not reduced and your code will grow.
-
There are still ways to abuse this scheme. You can pass the wrong bitset to the wrong register, for example. But it's an order of magnitude harder to get anything wrong.
-
A small sprinkling of template code allows us to avoid repeated definition of bitRead / bitWrite . This is shown in Listing 11.
Conclusion
OK, this isn't rocket science, and there's no scary template metaprogramming in sight (which, if you've seen the average embedded programmer, is no bad thing!) But this is a robust technique that exploits a number of C++'s features to provide safe and efficient hardware register access. Not only is it supremely readable and natural in the C++ idiom, it prevents many common register access bugs and provides extreme flexibility for hardware access tracing and debugging.
I have a number of proto-extensions to this scheme to make it more generic (using a healthy dose of template metaprogramming, amongst other things). I'll gladly share these ideas on request, but would welcome some discussion about this.
Do Overload readers see any ways that this scheme could be extended to make it simpler and easier to use?
[ 1 ] General Purpose Input/Output - assignable control lines not specifically designed for a particular data bus.
