








A parser is a fundamental tool in software development. Stuart Golodetz looks at how you might tackle writing one.
In my opinion, writing a parser manually is something everyone should do once. Any less than that, and you'd be missing out on an interesting bit of coding; any more, and you'd make the efforts put into Lex and Yacc [ LexYacc ] to save you the time and trouble (and the risk of making silly mistakes) look like a waste. (Lex and Yacc take lexical and grammar rules as input, respectively, and produce code in a language such as C to do the actual lexing and parsing. Modifying the input rules is substantially easier than modifying actual code, hence the reductions in necessary time and errors.)
Accordingly, in this article I'm going to discuss how you go about writing a simple parser for XML in C++ (without worrying too much about adhering 100% to the XML specification, since that's not the primary focus here). To more experienced readers, this may seem quite simple: in that case, I very much welcome comments/bug reports! To anyone who has never done any parsing before, hopefully this article will provide a useful introduction to the topic.
The plan
Our goal here is to turn a source XML file into an abstract syntax tree, or AST (see Listing 1). Once we have the AST, information from it (and thus from the file from which it was created) can be easily extracted for use in other code. The whole process is a (very) well-studied problem in computer science, partly because it forms part of the front-end of the compilation process [ DragonBook ]. (So this is exactly the sort of thing that happens behind the scenes when you compile your programs.)
As Listing 1 shows, there are two key steps to the process: lexical analysis, and parsing itself. Lexical analysis (lexing, for short) is the process of converting a source file to a sequence of tokens to be consumed by the parser. For instance, the text
// Source File:
<article type="short">
<para text="Not much" font="Arial"/>
</article>
// (Lexical Analysis)
// Token Sequence:
LBRACKET, IDENT("article"), IDENT("type"),
EQUALS, VALUE("short"), RBRACKET, LBRACKET,
IDENT("para"), ..., LSLASH, IDENT("article"),
RBRACKET
// (Parsing)
Abstract Syntax Tree:
XMLElement article [type="short"]
XMLElement para [text="Not much", font="Arial"]
|
| Listing 1 |
It is important to note that the two steps can run concurrently. The parser generally doesn't need to see the entire token sequence at once. Rather, a pipeline approach is used. The parser queries the lexer when it wants the next token, and the lexer reads the source file as necessary in order to produce it. The advantage of this approach is that fewer tokens need to be held in memory at any one time; additionally, it makes the local decision-making nature of the parser explicit.
Lexing XML
The first step when building a lexer is to decide what types of token it should output. If you're lucky in having some sort of formal specification for the language to hand, this may already have been done for you; if not, you'll have to invent one by looking at representative example source files and deducing the structure of the language. In this instance, we'll do the latter. The source file in Listing 1 is representative of the XML files we want to support. With a bit of creativity, it doesn't take much effort to come up with the possible token list shown in Table 1.
|
||||||||||||||||
| Table 1 |
The next question is how to convert the source into tokens. This is generally done using a finite state machine: we read characters from the source and change states until we're sure we've read a token, at which point we yield it to the parser. A certain amount of lookahead is sometimes required for this: for instance, when we read a < here, we don't know whether it's an LBRACKET token, or the first character of an LSLASH . To find out, we have to read in an additional character from the source file and check whether it's a / . If it is, we yield an LSLASH token; if not, we yield an LBRACKET and push whatever character we actually read onto a lookahead list: it's the first character of the next token, so we can't simply discard it.
The design of a finite state machine for the XML lexer is shown in Figure 1. The key things to note are the extra states needed to handle things like RSLASH and VALUE tokens. For example, when reading an RSLASH token, we read the / first and end up in the HALF RSLASH state. If we then see a > , we've read a whole RSLASH token and can yield it; if we see anything else, there's an error in the source file. Note that the " self-transition from HALF VALUE just means 'keep reading characters until we encounter a " or the end of the file, denoted <eof> '.
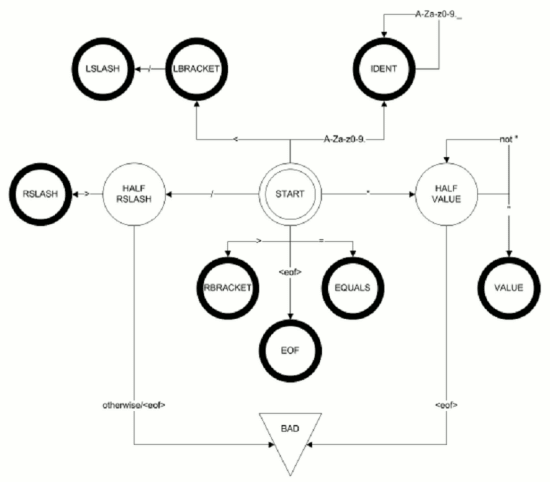
|
| Figure 1 |
Certain details of the lexer are difficult to show in a finite state machine graph. In particular, the data payloads yielded for IDENT and VALUE tokens are not shown. Also, what happens when we reach the end of the file whilst reading a token? If the token could be finished (for instance, we encounter <eof> whilst in the IDENT state), then we yield the token and set the state to EOF . If the token definitely isn't finished, we instead transition to the BAD state (and thereby throw an exception). The details can be seen in the code in Listing 2.
XMLToken_Ptr XMLLexer::next_token()
{
if(m_state == LEX_EOF) return XMLToken_Ptr();
else m_state = LEX_START;
std::string value;
for(;;)
{
switch(m_state)
{
case LEX_START:
{
unsigned char c = next_char();
if(m_eof) { m_state = LEX_EOF; }
else if(c == '=') {
m_state = LEX_EQUALS; }
else if(c == '/') {
m_state = LEX_HALF_RSLASH; }
else if(c == '"') {
m_state = LEX_HALF_VALUE; }
else if(c == '<') {
m_state = LEX_LBRACKET; }
else if(c == '>') {
m_state = LEX_RBRACKET; }
else if(isalpha(c) || isdigit(c) ||
c == '.') { m_state = LEX_IDENT;
value += c; }
break;
}
case LEX_EOF:
{
return XMLToken_Ptr();
}
case LEX_EQUALS:
{
return XMLToken_Ptr(
new XMLToken(XMLT_EQUALS, ""));
}
case LEX_HALF_RSLASH:
{
unsigned char c = next_char();
if(m_eof) {
m_state = LEX_BAD; value = ">"; }
else if(c == '>') {
m_state = LEX_RSLASH; }
else { m_state = LEX_BAD; value = ">"; }
break;
}
case LEX_HALF_VALUE:
{
unsigned char c = next_char();
if(m_eof) {
m_state = LEX_BAD; value = "\""; }
else if(c == '"') { m_state = LEX_VALUE; }
else { value += c; }
break;
}
case LEX_IDENT:
{
unsigned char c = next_char();
if(m_eof)
{
m_state = LEX_EOF;
return XMLToken_Ptr(new XMLToken(
XMLT_IDENT,value));
}
else if(isalpha(c) || isdigit(c) ||
c == '.' || c == '_')
{
value += c;
}
else
{
m_lookahead.push_back(c);
return XMLToken_Ptr(new XMLToken(
XMLT_IDENT, value));
}
break;
}
case LEX_LBRACKET:
{
unsigned char c = next_char();
if(m_eof)
{
m_state = LEX_EOF;
return XMLToken_Ptr(new XMLToken(
XMLT_LBRACKET, ""));
}
else if(c == '/')
{
m_state = LEX_LSLASH;
}
else
{
m_lookahead.push_back(c);
return XMLToken_Ptr(new XMLToken(
XMLT_LBRACKET, ""));
}
break;
}
case LEX_LSLASH:
{
return XMLToken_Ptr(new XMLToken(
XMLT_LSLASH, ""));
}
case LEX_RBRACKET:
{
return XMLToken_Ptr(new XMLToken(
XMLT_RBRACKET, ""));
}
case LEX_RSLASH:
{
return XMLToken_Ptr(new XMLToken(
XMLT_RSLASH, ""));
}
case LEX_VALUE:
{
return XMLToken_Ptr(new XMLToken(
XMLT_VALUE, value));
}
default: // case LEX_BAD
{
throw Exception("Error: Expected " + value);
}
}
}
}
unsigned char XMLLexer::next_char()
{
if(m_lookahead.empty())
{
unsigned char c = m_is.get();
if(m_is.eof()) m_eof = true;
return c;
}
else
{
unsigned char c = m_lookahead.front();
m_lookahead.pop_front();
m_eof = false;
return c;
}
}
|
| Listing 2 |
Writing the parser
Having written the lexical analyser, we can now turn our attentions to parsing proper. The grammar for the language we are trying to parse is shown in Listing 3. It's worth noting that the opening and closing tags for a composite element must have the same identifier, so the grammar is not context-free. Furthermore, as written, the grammar accepts documents with multiple root elements (this is not standard XML, but it will make the parser more flexible).
CompositeElement -> LBRACKET IDENT(name) Params
RBRACKET Elements LSLASH IDENT(name) RBRACKET
Document -> Elements
Element -> SimpleElement | CompositeElement
Elements -> <empty> | Element Elements
Param -> IDENT EQUALS VALUE
Params -> <empty> | Param Params
SimpleElement -> LBRACKET IDENT Params RSLASH
|
| Listing 3 |
We'll write a recursive descent-style parser here for simplicity. The top-level parsing function (that for documents) is shown in Listing 4. It creates the root node of the AST and then parses a sequence of XML elements and adds them as children of the root.
XMLElement_CPtr XMLParser::parse()
{
XMLElement_Ptr root(new XMLElement("<root>"));
std::list<XMLElement_Ptr> children =
parse_elements();
for(std::list<XMLElement_Ptr>::
const_iterator it=children.begin(),
iend=children.end(); it!=iend; ++it)
{
root->add_child(*it);
}
return root;
}
|
| Listing 4 |
The function to parse elements (see Listing 5) reads in elements while there are any remaining, and adds them to a list. This list is then returned.
std::list<XMLElement_Ptr> XMLParser::parse_elements()
{
std::list<XMLElement_Ptr> elements;
XMLElement_Ptr element;
while(element = parse_element())
{
elements.push_back(element);
}
return elements;
}
|
| Listing 5 |
The remaining parsing function (see Listing 6), which reads in an individual XML element, is the real core of the parser. It starts by trying to read in the next token. If there isn't a next token, then there's no element to parse, so we (effectively) return NULL ; if there is, but it's not < (the opening token for an element), then we add whatever token we actually did read to the lookahead list and also return NULL . This happens when we reach the end tag of the enclosing XML element, e.g. if we read <article><para/></article> , this will happen when we reach the LSLASH token at the start of </article> .
XMLElement_Ptr XMLParser::parse_element()
{
XMLToken_Ptr token;
token = read_token();
if(!token)
{
// If there are no tokens left, we're done.
return XMLElement_Ptr();
}
if(token->type() != XMLT_LBRACKET)
{
// If the token isn't '<', we're reading
// something other than an element.
m_lookahead.push_back(token);
return XMLElement_Ptr();
}
token = read_checked_token(XMLT_IDENT);
XMLElement_Ptr element(new XMLElement(
token->value()));
token = read_token();
while(token && token->type() == XMLT_IDENT)
// while there are attributes to be processed
{
std::string attribName = token->value();
read_checked_token(XMLT_EQUALS);
token = read_checked_token(XMLT_VALUE);
std::string attribValue = token->value();
element->set_attribute(attribName,
attribValue);
token = read_token();
}
if(!token) throw Exception(
"Token unexpectedly missing");
switch(token->type())
{
case XMLT_RBRACKET:
{
// This element has sub-elements, so parse
// them recursively and add them to the
// current element.
std::list<XMLElement_Ptr> children =
parse_elements();
for(std::list<XMLElement_Ptr>::
const_iterator it=children.begin(),
iend=children.end(); it!=iend; ++it)
{
element->add_child(*it);
}
// Read the element closing tag.
read_checked_token(XMLT_LSLASH);
token = read_checked_token(XMLT_IDENT);
if(token->value() != element->name()) throw
Exception("Mismatched element tags:
expected " + element->name() + " not "
+ token->value());
read_checked_token(XMLT_RBRACKET);
break;
}
case XMLT_RSLASH:
{
// The element is complete, so just break
// and return it.
break;
}
default:
{
throw Exception("Unexpected token type");
}
}
return element;
}
void XMLParser::check_token_and_type(
const XMLToken_Ptr& token,
XMLTokenType expectedType)
{
if(!token)
{
throw Exception("Token unexpectedly missing");
}
if(token->type() != expectedType)
{
throw Exception("Unexpected token type");
}
}
XMLToken_Ptr XMLParser::read_checked_token(
XMLTokenType expectedType)
{
XMLToken_Ptr token = read_token();
check_token_and_type(token, expectedType);
return token;
}
XMLToken_Ptr XMLParser::read_token()
{
if(m_lookahead.empty())
{
return m_lexer->next_token();
}
else
{
XMLToken_Ptr token = m_lookahead.front();
m_lookahead.pop_front();
return token;
}
}
|
| Listing 6 |
Assuming we're actually parsing an element, the next step is to read in the element identifier (e.g. article). To read in any parameters, we then read the next token to see whether it's an IDENT : if so, we keep reading to find the rest of the parameter and iterate. Note that any erroneous tokens we might encounter are handled using read_checked_token() , which will throw an exception if the token we read is of the wrong type.
When the next token is no longer an IDENT (i.e. when we've reached the end of the parameter list), we check to see whether we're dealing with a simple element or a complex element. If the former, we'll encounter an ending RSLASH . If the latter, we'll instead see an RBRACKET , at which point we recursively read in any sub-elements, followed by the closing element tag, carefully checking that the names match in the process. Either way, we return the element once it's complete.
Elementary, Watson
The only remaining piece of the puzzle is the design of the XMLElement class: how do we actually represent and use the AST generated by the parser? The structure I came up with is shown in Listing 7.
typedef shared_ptr<class XMLElement>
XMLElement_Ptr;
typedef shared_ptr<const class XMLElement>
XMLElement_CPtr;
class XMLElement
{
private:
typedef std::map<std::string,
std::string> AttribMap;
typedef AttribMap::const_iterator AttribCIter;
typedef std::map<std::string,
std::vector<XMLElement_CPtr> > ChildrenMap;
typedef ChildrenMap::const_iterator ChildrenCIter;
private:
std::string m_name;
AttribsMap m_attributes;
ChildrenMap m_children;
public:
XMLElement(const std::string& name);
public:
void add_child(const XMLElement_Ptr& child);
const std::string& attribute(
const std::string& name) const;
std::vector<XMLElement_CPtr> find_children(
const std::string& name) const;
XMLElement_CPtr find_unique_child(
const std::string& name) const;
bool has_attribute(
const std::string& name) const;
bool has_child(const std::string& name) const;
const std::string& name() const;
void set_attribute(const std::string& name,
const std::string& value);
};
XMLElement::XMLElement(const std::string& name)
: m_name(name)
{}
void XMLElement::add_child(
const XMLElement_Ptr& child)
{
m_children[child->name()].push_back(child);
}
const std::string& XMLElement::attribute(
const std::string& name) const
{
AttribCIter it = m_attributes.find(name);
if(it != m_attributes.end()) return it->second;
else throw Exception( "The element does not have
an attribute named " + name);
}
std::vector<XMLElement_CPtr>
XMLElement::find_children(
const std::string& name) const
{
ChildrenCIter it = m_children.find(name);
if(it != m_children.end()) return it->second;
else return std::vector<XMLElement_CPtr>();
}
XMLElement_CPtr XMLElement::find_unique_child(
const std::string& name) const
{
ChildrenCIter it = m_children.find(name);
if(it != m_children.end())
{
const std::vector<XMLElement_CPtr>&
children = it->second;
if(children.size() == 1) return children[0];
else throw Exception( "The element has more
than one child named " + name);
}
else throw Exception(
"The element has no child named " + name);
}
bool XMLElement::has_attribute(
const std::string& name) const
{
return m_attributes.find(name) !=
m_attributes.end();
}
bool XMLElement::has_child(
const std::string& name) const
{
return m_children.find(name) !=
m_children.end();
}
const std::string& XMLElement::name() const
{
return m_name;
}
void XMLElement::set_attribute(
const std::string& name,
const std::string& value)
{
m_attributes[name] = value;
}
|
| Listing 7 |
There's nothing particularly complicated about this bit, so I won't dwell on it. What is worth illustrating instead is how easy it is to use (see Listing 8, which shows a snippet of code from a function to load an Ogre mesh file [ Ogre ]).
XMLLexer_Ptr lexer(new XMLLexer(filename));
XMLParser parser(lexer);
XMLElement_CPtr root = parser.parse();
XMLElement_CPtr meshElt
= root->find_unique_child("mesh");
XMLElement_CPtr submeshesElt
= meshElt->find_unique_child("submeshes");
std::vector<XMLElement_CPtr> submeshElts
= submeshesElt->find_children("submesh");
size_t submeshCount = submeshElts.size();
std::vector<Submesh_Ptr> submeshes;
for(size_t i=0; i<submeshCount; ++i)
{
const XMLElement_CPtr& submeshElt
= submeshElts[i];
std::string materialName
= submeshElt->attribute("material");
//...
|
| Listing 8 |
Other parsers near you
There's a lot more to parsing than I've been able to show here with a simple example. Parsers in general can be either top-down or bottom-up (the recursive descent parser shown in this article is an example of the former). Top-down parsers try and turn the start symbol of the grammar (e.g. in our example in Listing 3, this would be Document ) into the token sequence observed, by replacing left-hand sides of productions with right-hand sides. For example, in our case, we start off knowing we have a Document , which means we must have a sequence of Elements , etc. The alternative is bottom-up parsing. This starts from the observed token sequence and tries to turn it into the start symbol by applying production rules in reverse. For instance, if we see IDENT EQUALS VALUE , we know we're dealing with a Param , and so on.
Different parsing algorithms have different strengths and weaknesses: generally speaking, there's a trade-off between how general a grammar a parser can recognise, and the runtime and implementation costs (i.e. the more general parsers tend to be harder to implement and take longer to run). To give you a flavour of some of the algorithms out there, here's a quick description of a few alternatives:
-
Table-based LL parser (top-down).
Calling the left-hand sides of productions 'non-terminals' and the actual tokens like IDENT , etc., 'terminals', this sort of parser takes a numbered series of rules and a parse table of type Terminal x Non-Terminal -> Rule Number. It operates using a stack, which initially contains only the starting non-terminal. It iteratively examines the top element of the stack and the next character in the input stream. If the top element of the stack is a terminal, then either it matches the next input character (in which case they are consumed), or it doesn't (there's a syntax error). If the top element is a non-terminal, the correct rule to apply is looked up in the parse table (indexing on the top stack element and the next input character), and the top stack element is replaced with the right-hand side of the appropriate rule (note that the input character is not consumed). If there's no rule for this case in the parse table, there must be a syntax error.Finally, if the stack is empty, then either there's no next input character (we're done parsing), or there is (yet another type of syntax error).
-
Shift-reduce parser (bottom-up).
This works using a stack and the input sequence. At each iteration, it decides whether to shift (push the next input token onto the stack) or reduce (apply a grammar rule to the things on top of the stack). The goal is to empty the input sequence and reduce the stack to the start symbol.
-
GLR (Generalized Left-to-right Rightmost derivation) parser.
A hardcore parser designed for nondeterministic and ambiguous grammars.
If you're interested in parsing, I advise you to have a read through [ DragonBook ]; it contains a lot of very interesting stuff. It has to be emphasised, however, that these days parsing is considered essentially a solved problem. If you need a parser for real-world use, it's rarely the case that you should roll your own: you're usually much better off using Yacc or something like it [ LexYacc ]. (You might also want to investigate the Spirit parser framework: indeed I'm reliably informed that there have been a couple of Overload articles [ Guest04 , Penhey05 ] about it before!) All the same, it's always a good idea (and indeed fun) to understand what these things are doing under the hood as well.
Conclusion
In this article, I've shown how to construct a basic XML parser (email me if you want the full source code) and given a brief overview of some other types of parser you might like to investigate. It's worth noting that often one of the problems you're likely to have with parsing is not actually in reading text that is syntactically valid: it's dealing with invalid text and outputting suitable error messages. This is a particular problem for compilers. Whilst it's outside the scope of this article, one of the problems is that good error messages have to be readable by humans in order to help them correct the error: this often requires an understanding of intent. Another issue is that stopping at the first parse error you encounter often isn't good enough: real-world parsers need to carry on and attempt to parse the rest of the input, and we'd ideally like them not to output a load of spurious error messages while they're doing it. All in all, it's a fascinating topic, and something I highly recommend investigating further. n
Acknowledgements
Many thanks to the Overload review team for the many improvements suggested to the original article.
References
[DragonBook] Compilers: Principles, Techniques and Tools (1st Ed.), A Aho, R Sethi, J D Ullman, Addison Wesley, January 1985.
[Guest04] 'Mini-project to Decode a Mini-language', Thomas Guest, Overload #64, December 2004.
[LexYacc] The Lex and Yacc Page, http://dinosaur.compilertools.net
[Ogre] Open Source 3D Graphics Engine, http://www.ogre3d.org
[Penhey05] 'With Spirit', Tim Penhey, Overload #69, October 2005.
