








Designing programs for multi-core systems can be extremely complex. Anthony Williams suggests some patterns to keep things under control.
There are many ways of structuring parallel programs, and you’d be forgiven for finding it difficult to identify the best solution for a given problem. In this series of articles I’m going to describe some common patterns for structuring parallel code, and for communicating between the different parts of your program that are running in parallel. I’m also going to provide some basic guidelines for choosing which patterns to use in a given scenario.
This article will describe some simple structural patterns; further structural patterns and communication patterns will be covered in later articles.
Structural patterns
Structural Patterns are about the general ‘shape’ of a solution: how the data and tasks are divided between threads, how many threads are used, and so forth. Each structural pattern has a different set of trade-offs with regards to performance, scalability, and so forth. Which pattern to choose depends strongly on the characteristics of the particular problem being solved.
We’ll start by looking at Loop Paralellism .
Loop parallelism
The most basic of structural patterns is Loop Parallelism . The basic premise is that you have something like a for loop that applies the same operation to many independent data items.
This is your classic embarrasingly parallel scenario, and scales nicely across as many processors as you've got, up to the number of data items – if you’ve only got 5 data items to process you cannot make use of more than 5 processors with a single layer of loop parallelism.
This is such a common and simple scenario that frameworks for concurrency and parallelism frequently provide a
parallel_for_each
operation or equivalent. e.g.
std::vector<some_data> data;
parallel_for_each(data.begin,
data.end(),
process_data);
or, for a compiler that supports OpenMP:
#pragma omp parallel for
for(unsigned i=0;i<data.size();++i) {
process_data(data[i]);
}
The key thing to remember about Loop Parallelism is that the operation in the loop must depend solely on the loop counter value, and the execution for one loop iteration must not interact with the data used by any other loop iteration. This is absolutely crucial since the order of execution of iterations cannot be guaranteed, and may vary from run to run or from machine to machine. Consequently you cannot guarantee that iterations would be run in the correct order for any loop-carried dependencies and concurrent access to the same variables can lead to a data race and undefined behaviour.
Though some frameworks provide mechanisms for handling such loop-carried dependencies, the presence of such dependencies typically means that your problem is not ideally suited to loop parallelism, and an alternative pattern may be more appropriate.
Fork/Join
Also called ‘divide and conquer’, the essential idea of the fork/join pattern is that a task is divided into two or more parts, tasks are run in parallel (forked off) to process these parts, and then the driver code waits for these parallel tasks to finish (joins with them).
The Fork/Join pattern is often used recursively with each task being subdivided into its own set of parallel tasks, until the task cannot usefully be divided any further. Listing 1 shows how such a recursive technique could be used to implement a parallel Fast Fourier Transform algorithm for a power-of-2 FFT.
template<typename Iter>
void do_fft_step(Iter first,Iter last) {
unsigned long const
length=std::distance(first,last);
if(length<minimum_fft_length) {
do_serial_fft_step(first,last);
} else {
Iter const mid_point=first+length/2;
auto top=std::async([=]{
do_fft_step(first,mid_point);});
do_fft_step(mid_point,last);
top.wait();
merge_fft_halves(first,mid_point,last);
}
}
template<typename Iter>
void parallel_fft(Iter first,Iter last) {
prepare_fft(first,last);
do_fft_step(first,last);
finalize_fft(first,last);
}
|
| Listing 1 |
In this case the merging steps mean that you can’t readily process each section independently with loop parallelism, but the recursive division allows for parallel execution of the smaller steps.
This uses
std::asyn
c with the default launch policy, so the C++ runtime can decide how many threads to spawn for the
std::async
tasks, and switch to using synchronous tasks which run in the waiting thread rather than asynchronous tasks when there are too many threads running. Also, rather than submitting a second
async
task for the ‘bottom half’ we execute this directly. This avoids the overhead of creating the
std::async
data structures, and potentially creating a new thread for the task when the current thread is just going to wait anyway. Put together, this therefore allows the task to scale with the number of processors.
Fork/Join works best at the top level of the application, where you are in control of how many tasks are running in parallel – if it is used deep within the implementation of an already-parallel algorithm then you may well find that all the available hardware parallelism is already being used by other parts of the application, so there is no benefit. You also need to be able to see how many existing tasks are running in parallel, so that you can avoid excessive oversubscription of the processors.
By its very nature, the Fork/Join pattern produces ‘bursty’ concurrency – initially there is no concurrency, then there is a ‘burst’ of parallel tasks, then they are joined and there is again no concurrency. If your application is done after one such cycle then this is fine, but if your application requires a number of Fork/Join cycles then there is spare processing power that could potentially be used during each join/re-fork period.
Finally, you need to watch for uneven workloads between the tasks – if one task finishes much later than the others then you are wasting any hardware parallelism that could potentially be used whilst the master task is waiting for the long-running task to finish. e.g. if you are searching for prime numbers then you don’t want to divide your number-line into equally-sized ranges – it is much quicker to check the lower numbers for primality than the higher ones, so if each task deals with 1 million numbers, the task starting at 1 will finish much quicker than the task starting at 100 trillion.
Pipelines
The Pipeline pattern handles the scenario where you have a set of tasks that must be applied in sequence, the output of one being the input to the next, and where this sequence of tasks must be applied to every item in a large data set.
As you would expect for a pipeline, the order of the data that goes through the pipeline is preserved – the data that comes out the end first is the result of applying the operations in the pipeline to the data that was put in to the pipeline first, and so forth.
Another characteristic of pipelines is that there is a startup period, during which the pipeline is being filled, and thus the parallelism is reduced. Initially there is only one data item in the pipeline, being processed by the first task; once that is done then a new item can be processed by the first task, whilst the first item is processed by the second task. Once the first item has made it all the way through the pipeline, the pipeline will remain at maximum parallelism until the last item is being processed. There will then be a draining of the pipeline, as the last item makes its way through each task, the parallelism reducing with each step. (See Figure 1.)
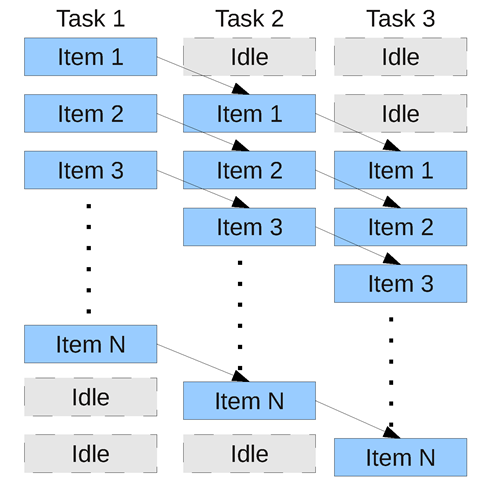
|
| Figure 1 |
As should be obvious, the maximum parallelism that can come from the pipeline itself is the number of tasks in the pipeline. If you have more hardware parallelism available then this will not be utilised without further thought. One possibility is to use parallelism within each pipeline stage (which may well lead to ‘bursty’ parallelism as we saw with fork/join), and another is to run multiple pipelines in parallel (in which case you need to be careful that the order is preserved if it is important).
Either way, it is important to ensure that the pipeline stages are all of similar duration – if one stage takes much longer than the others then it will limit the rate at which data can be processed, and thus processors running other stages will potentially be running idle as they wait for the long running stage to complete.
One potential downside of pipelines is the way they interact with caches. If each task is fixed to a single processor, then as stage N finishes processing a data item, the output of stage N has to be transferred from the cache of the processor running stage N to the cache of the processor running stage N +1. Depending on the complexity of the task and the size of the data, this may take a significant amount of time.
The alternative is to have the whole pipeline run on each processor, with some additional logic to ensure that any required ordering between data items is preserved. This has the benefit that the data no longer has to be transferred between caches, as it is right there waiting for the next task in the pipeline. However, in this case it is the code for the task that must be loaded into the instruction cache – by running the whole pipeline on each processor we increase the chance that the code for each stage has been dropped from the cache, and will thus have to be reloaded. Again, this can take a noticable amount of time.
As with everything, if performance is important, then time various options and choose the best for your particular application.
Actor
The Actor model is basically message passing Object Orientation with concurrency. Message sending is asynchronous, so the code that sends a message does not wait for the receiving object to handle it, and each object (actor) responds to incoming message asynchronously on its own thread. This is the model used by Erlang, where each Erlang process is an Actor. It is also similar to the model used by MPI, and essentially synonymous with Hoare’s Communicating Sequential Processes. (See Figure 2.)
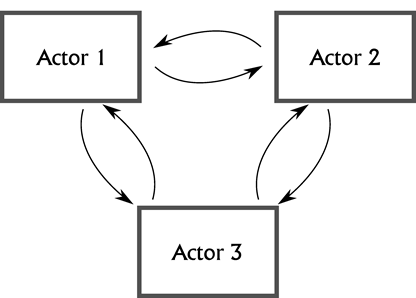
|
| Figure 2 |
In its purest form, there is no shared state in the Actor model, and all communication is done via the message queues. Some languages (such as Erlang) enforce this; in C++ it is your responsibility to follow the rules.
The prime benefit is that each actor can be analysed independently of the others – incoming messages are queued until the actor is ready to receive a message so it is only the order of messages that matters. You can therefore test that each actor sends out the appropriate sequence of messages given a particular input sequence. If you stick to the rule that the only communication between actors is via the message queues (no shared mutable state) then such basic testing is sufficient, and it is certainly much easier than testing multiple interacting threads.
The lack of shared mutable state has another benefit – data races are impossible. You can still potentially get race conditions, where two or more actors send a message to the same recipient, and the order the messages arrive affects the outcome, but this is easier to handle as you can just test with all possible order combinations and verify that the recipient does something sensible in each case.
Another benefit is that the independence makes actors easy to reason about, as each can be considered on its own. You can, for example, make each actor a state machine with well-defined transitions and behaviours.
One downside is that actors are not good for short-lived tasks, as the overhead of setting up an actor and managing the message queue can outweigh the benefits. Also, message passing isn’t always the ideal communication mechanism; sometimes it’s just more efficient to carefully synchronize access to shared state.
Finally, the scalability is limited to the number of actors – if you’ve only got 3 actors then the actor model won’t scale to more than 3 processing cores unless you can make use of additional concurrency within each actor. Of course, many problems can be divided into very fine-grained tasks and thus be constructed out of lots of actors, but this then relates back to the task size – there is no point generating an actor just to add two integers, as even the message passing overhead will far exceed the actual cost of the operation.
Listing 2 shows a simple use of actors in C++, with each actor sending a message to the other, and then waiting for the next message in return.
int main() {
struct pingpong { jss::actor_ref sender; };
jss::actor pp1([] {
for(;;) {
jss::actor::receive().match<pingpong>(
[](pingpong p) {
std::cout<<"ping\n";
p.sender.send(
pingpong{jss::actor::self()});
});
} });
jss::actor pp2([] {
for(;;) {
jss::actor::receive().match<pingpong>(
[](pingpong p) {
std::cout<<"pong\n";
p.sender.send(
pingpong{jss::actor::self()});
});
} });
pp1.send(pingpong{pp2});
}
|
| Listing 2 |
Next time
In part 2 of this article I’ll cover more structural patterns, starting with Speculative Execution .
