








Annotating text automatically requires word disambiguation. Silas Brown introduces the Yarowsky algorithm to help.
In 1997 I wrote a CGI script in C++ to perform Web ‘mediation’. It took the address of a Web page, fetched it, modified the markup so as to simplify complex layouts (so they work better in large print) and to overcome various other disability-related limitations of early Web browsers, and sent the result to the user’s browser. Additionally, all links on the page were changed to point back through the system, so the user could surf away on this modified version of the Web without needing to be able to set the proxy settings on the computers they used.
This ‘Web Access Gateway’ was not the first or the only effort at Web adaptation, but for a time it was, I think, the most comprehensive. For some years it was run on ACCU’s server, in order not only to ensure the accessibility of ACCU’s site but also as a service to others; this resulted in ACCU being cited in an ACM publication courtesy of IBM’s blind researcher Chieko Asakawa [
Asakawa
]. It also was and still is run by organizations interested in displaying East Asian characters on devices that lack the fonts [
EDRDG
], since it has a function to replace characters by small bitmap images which are served by a small, single-threaded
select()
-based, HTTP 1.0 server and some public domain fonts.
The Access Gateway became less useful with the advent of Web 2.0 and Javascript-heavy sites. I did try to handle basic navigation-related scripts, but not serious AJAX. However, by this time desktop browsers were improving, and user stylesheets [ ACG ] became more appropriate than mediators, although user stylesheets still can’t solve everything. There was also a demand for mediators to do ‘content adaptation’ for mobile phone browsers (especially the lower-end, non-smartphone variety), and indeed at one time I (somehow) obtained a part-time job on the development team of a custom server for mobile operators to run [ Openwave ]. This one was built around the SpiderMonkey Javascript interpreter so it wouldn’t have any trouble with AJAX, although we still had to implement the DOM and that was a hard game of ‘keep up with the browsers’. Opera Mini had it easier because they already had some browser code. (They also write their own user clients instead of making do with whatever’s on the phone. I wish they’d allow larger fonts though.)
Recently I wanted to help a group of smartphone-using friends to access a Chinese-language reference site. I wished to add automatic ‘pinyin’ pronunciation aids to the site for them. The site was AJAX-heavy and I had not kept any of the Openwave code, but it occurred to me that writing a mediator with modern technologies can be done in a much simpler way. My Openwave no-compete contract has long since expired and I felt free to break out the modern tools and build a 21st-century mediator. It’s quite exciting to be able to reproduce in just one or two afternoons of coding something that previously needed many years of development.
Modern server tools
With apologies to other programming languages, I coded the server in Python. Python makes it quick to try things out, and has many Web-related modules in its standard library. Moreover, it has the Tornado web framework [ Tornado ], which allowed me to make the entire server (not just the bitmap-serving part) a single-threaded, super-scalable affair with support for HTTP 1.1 pipelining and other goodies thrown in for free. Then there is the Python Imaging Library [ PIL ] which allowed me to do the character-rendering part in Freetype with better fonts (not to mention more flexible rendering options). For good measure, I added an option to call external tools to re-code MP3 audio to reduce the download size, and to add a text-only option to PDF links. (Both of these can be useful for low-speed mobile links in rural areas.)
How did I call an external processing tool from a single-threaded Tornado process without holding up the other requests? Well it turns out that Tornado can cope with your use of other threads so long as the completion callback is called from the Tornado thread, which can be arranged by calling
IOLoop.instance().add_callback()
. For more details please see my code [
Adjuster
].
What about handling all the AJAX and ensuring that all links etc are redirected back through the system? This time round, I didn’t have to do nearly so much. As the server is Tornado-based and handles all requests to its port (rather than being CGI-based and handling only URIs that start with a specific path), it is possible to mediate a site’s URIs without actually changing any of those URIs except for the domain part. Most Javascript code doesn’t care what domain it’s running on, and it’s extremely rare to find a script that would be broken by straightforward changes to any domain names mentioned in its source. Therefore, as long as the browser itself is sufficiently capable, it is not necessary to run Javascript on the server just to make redirection work. If you have a wildcard domain pointing to your server (i.e. it is possible to put arbitrary text in front of your domain name and it will still resolve to your server), you can mediate many sites in this way. There are a few details to get right, such as cookie handling, but it’s nowhere near as complex as using a script interpreter.
Text annotation
For adding the pronunciation aids to the site it was necessary to make a text annotator. In order to make it as easy as possible for others to use their own annotators instead, I kept this in a completely separate process that takes textual phrases on standard input and emits the annotated versions to standard output; for efficiency it is called with all phrases at once, and the results are put back into the HTML or JSON in their appropriate places by the mediator. Therefore the authors of text annotators do not need to worry about HTML parsing, although they still have the option of including HTML in its output. For example, with appropriate CSS styling, HTML’s Ruby markup can be used to place annotations over the base text (see the source code to my page on Xu Zhimo’s poem [ Xu ] for one way to do this).
The simplest approach to annotating text is to apply a set of search-and-replace criteria, perhaps driven by a dictionary, but problems can arise when there is more than one way to match a section of text to the search strings, especially in languages that do not use spaces and there is more than one way to interpret where the word boundaries are. The lexer generator Flex [ Flex ], which might be useful for ‘knocking up’ small annotators that don’t need more rules than flex can accommodate, always applies the longest possible match from the current position, which might be adequate in many sentences but is not always.
As a result of my being allowed access to its C source, Wenlin software for learning Chinese [ Wenlin ] now has a function for guessing the most likely word boundaries and readings of Chinese texts, by comparing the resulting word lengths, word usage frequencies according to Wenlin’s hand-checked data from the Beijing Language Institute, and some Chinese-specific ‘rules of thumb’ I added by trial and error. The resulting annotations are generally good (better than that produced by the tools of Google et al ), but I do still find that some of the obscure multi-word phrases I add to my user dictionary are not for keeping track of any definitions or notes so much as for ensuring that Wenlin gets the boundaries and readings right in odd cases.
Annotator generator
If you are fortunate enough to have a large collection of high-quality, manually proof-read, example annotations in a computer-readable format, then it ought to be possible to use this data to ‘train’ a system to annotate new text, saving yourself the trouble of manually editing large numbers of rules and exceptions.
My first attempt at an examples-driven ‘annotator generator’ simply considered every possible consecutive-words subset of a phrase (word 1, word 2, words 1 to 2, word 3, words 2 to 3, words 1 to 3, etc; it’s a reasonable assumption that annotated examples will have word boundaries), and for each case tested to see if the annotation given to that sequence of words is always the same whenever that sequence of words occurs anywhere else in the examples. If so, it is a candidate for a rule, and rules are further restricted to not overlap with each other (this means we don’t have to deal with exceptions); the code takes the shortest non-overlapping rules that cover as much as possible of the examples, and turns them into C code consisting of many nested one-byte-at-a-time
switch()
constructs and function calls. (When generating code automatically, I prefer C over C++ if reasonable, because C compiles faster when the code is large.) Python was good for prototyping the generator, because it has many built-in functions to manipulate strings and lists of strings, count occurrences of an annotation in a text, etc, and it also has the
yield
keyword that can be used to make a kind of ‘lazy list’ whose next element is computed only when needed (if a function
yield
’s values, this creates an iterator over them which returns control to the function when the next value is asked for) so you can stop when enough rules have been accepted to cover the whole of an example phrase. The generator didn’t have to run particularly quickly, as long as it could produce a fast C program within in a day or so.
The problem with this approach is that restricting the generator to rules that have no exceptions or overlaps will typically result in rules that are longer than necessary (i.e. require a longer exact match with an example phrase) and that do not achieve 100% coverage of the examples (i.e. would not be able to reproduce all the example annotations if given the unannotated example text). This may be sufficient if you have a reasonable backup annotator to deal with any text that the examples-driven annotator missed, but it does seem like an under-utilisation of the information in the examples. We can however do better, especially if we break away from the idea of matching continuous strings of text.
Yarowsky-like algorithm
Yarowsky’s algorithm for word sense disambiguation [ Yarowsky ] used contextual cues around a word (not necessarily immediately adjacent to it) to try to guess which meaning it has (Yarowsky’s example used the English word ‘plant’, associating it with either ‘plant life’ or ‘manufacturing plant’, and using other words in the vicinity to guess which one was meant). Figure 1 shows how it gradually builds up rules to disambiguate ‘plant’ in phrases, adding a rule to spot ‘animal’ nearby. Although Yarowsky was originally talking about meaning, there’s no reason why it can’t be applied to pronunciation (which is often related to meaning) or to arbitrary other annotations, and there’s no reason why it shouldn’t work in a language that does not use word boundaries if we modify it to check for characters instead of words and use them to judge which character-based search/replace rules are appropriate and therefore how to decide word boundaries etc.
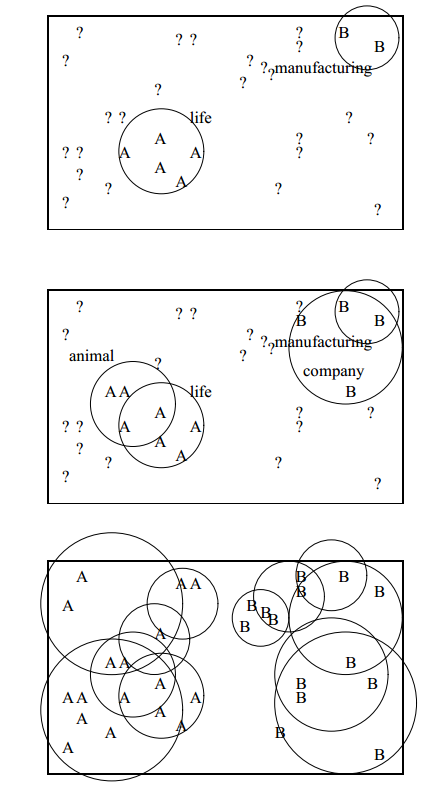
|
| Figure 1 |
Yarowsky started with manually-chosen ‘seed collocations’. With a fully-annotated set of examples it is possible to automatically list the candidate seed collocations along with a measure of how many correct and incorrect applications of the rule each would result in. (Yarowsky also suggested analysing the exact collocational relationships of the words, such as whether they are in a predicate-argument relationship, but this enhancement is hard to do for arbitrary languages.)
It is then possible to find additional collocations by considering an untagged (unannotated) text. The seed collocations are used to decide the sense of some of the words in that text, and, assuming these decisions to be correct, the system checks what other words are also found near them which might be used as new indicators. This process can be repeated until many other possible indicators have been found. However, if enough annotated examples have been provided it might be possible to skip this step and just use the seed collocations; this has the advantage of applying rules only when we have a greater degree of certainty that we can do so (an ‘if in doubt, leave it out’ annotation philosophy).
My
yarowsky_indicators()
function [
Generator
] takes the simplified approach of looking only for seed collocations of one or more complete Unicode characters within a fixed number of bytes of the end of the word match, prioritising the ones that are short and that cover more instances of the word, completely excluding any that would give false positives, and stopping as soon as all examples have been covered. Keeping to a fixed number of bytes around the end of the match makes it easier for the C parser to work from a local buffer. The algorithm to find the Yarowsky indicators is shown in Listing 1.
# This code will run several times faster if it
# has a dictionary that maps corpus string indices
# onto values of len(remove_annotations(c)) where
# c is the corpus up to that index.
def yarowsky_indicators(word_with_annotations,
corpus_with_annotations,
corpus_without_annotations):
# returns True if the given word's annotation is
# the majority sense and can be made default, or
# in minority senses lists the context
# indicators. Variation of first stage of
# Yarowsky's algorithm.
word_without_annotations = \
remove_annotations(word_with_annotations)
# First, find positions in
# corpus_without_annotations which correspond to
# where word_with_annotations occurs in
# corpus_with_annotations.
# Put this into the list okStarts.
lastS = lenSoFar = 0
okStarts = []
for s in \
re.finditer(re.escape(word_with_annotations),
corpus_with_annotations):
s = s.start()
lenSoFar += len(remove_annotations( \
corpus_with_annotations[lastS:s]))
lastS = s
assert corpus_without_annotations[ \
lenSoFar:lenSoFar
+ len(word_without_annotations)] \
== word_without_annotations
okStarts.append(lenSoFar)
# Now check for any OTHER matches in
# corpus_without_annotations, and put them
# into badStarts.
okStarts = set(okStarts)
badStarts = set(x.start() for x in
re.finditer(re.escape(word_without_annotations),
corpus_without_annotations)
if not x.start() in okStarts)
if not badStarts:
return True # this annotation has no false
# positives so make it default
# Some of the badStarts can be ignored on the
# grounds that they should be picked up by
# other rules first: any where the match does
# not start at the start of an annotation
# block (the rule matching the block starting
# earlier should get there first), and any
# where it starts at the start of a block that
# is longer than itself (a longest-first
# ordering should take care of this). So keep
# only the ones where it starts at the start
# of a word and that word is no longer
# than len(word_without_annotations).
lastS = lenSoFar = 0
reallyBadStarts = []
for s in re.finditer(re.escape(markupStart
+ word_without_annotations[0])
+ '.*?'
+ re.escape(markupMid),
corpus_with_annotations):
(s, e) = (s.start(), s.end())
if e - s > len(markupStart
+ word_without_annotations
+ markupEnd):
continue # this word is too long
# (see comment above)
lenSoFar += len(remove_annotations( \
corpus_with_annotations[lastS:s]))
lastS = s
if lenSoFar in badStarts:
reallyBadStarts.append(lenSoFar)
badStarts = reallyBadStarts
if not badStarts:
return True
# this annotation has no effective false
# positives, so make it default
if len(okStarts) > len(badStarts):
# This may be a majority sense. But be
# careful. If we're looking at a possible
# annotation of "AB", it's not guaranteed
# that text "ABC" will use it - this might
# need to be split into A + BC (not using the
# AB annotation). If we make
# word_with_annotations the default for "AB",
# then it will be harder to watch out for
# cases like A + BC later. In this case it's
# better NOT to make it default but to
# provide Yarowsky collocation indicators for
# it.
if len(word_without_annotations) == 1:
# should be safe
return True
if all(x.end() - x.start()
== len(markupStart
+ word_without_annotations)
for x in
re.finditer(re.escape(markupStart)
+ (re.escape(markupMid) + '.*?'
+ re.escape(markupStart)). \
join(re.escape(c)
for c in
list(word_without_annotations)),
corpus_with_annotations)):
return True
# If we haven't returned yet,
# word_with_annotations cannot be the "default"
# sense, and we need Yarowsky collocations for
# it.
omitStr = chr(1).join(bytesAround(s) for s in
badStarts)
okStrs = [bytesAround(s) for s in okStarts]
covered = [False] * len(okStrs)
ret = []
# unique_substrings is a generator function
# that iterates over unique substrings of
# texts, in increasing length, with equal
# lengths sorted by highest score returned by
# valueFunc, and omitting any where omitFunc is
# true
for indicatorStr in \
unique_substrings(texts=okStrs,
omitFunc=lambda txt: txt in omitStr,
valueFunc=lambda txt: sum(1 for s in
okStrs if txt in s)):
covered_changed = False
for i in xrange(len(okStrs)):
if not covered[i] and indicatorStr \
in okStrs[i]:
covered[i] = covered_changed = \
True
if covered_hanged:
ret.append(indicatorStr)
if all(covered):
break
return ret
|
| Listing x |
A remaining problem is that it often needs to find too many collocations to make up for the fact that the C parser’s handling of rule overlaps is so primitive, greedily matching the longest rule every time. If the parser had something like Wenlin’s frequency-driven approach then it might not need to rely on collocations so much, although collocations would still be useful sometimes. The ‘collocations’ found by
yarowsky_indicators()
are often not real collocations at all, but just strings that happen to be nearby in the example texts; this might cause strange matching behaviour in other texts. I hope to find ways to improve this situation in future.
References
[ACG] Accessibility CSS Generator, http://ssb22.user.srcf.net/css/
[Adjuster] Web Adjuster, http://ssb22.user.srcf.net/adjuster/
[Asakawa] Hironobu Takagi and Chieko Asakawa (IBM Japan). Transcoding proxy for nonvisual web access. ASSETS 2000. http://dl.acm.org/citation.cfm?id=354371 (click on References and check number 12)
[EDRDG] http://www.csse.monash.edu.au/~jwb/jviewer.html (the actual server is on arakawa.edrdg.org)
[Flex] http://flex.sourceforge.net
[Generator] Annotator Generator, http://ssb22.user.srcf.net/adjuster/annogen.html
[Openwave] http://www.openwave.com/solutions/traffic_mediation/web_adapter/index.html
[PIL] Python Imaging Library, http://www.pythonware.com/products/pil
[Tornado] http://www.tornadoweb.org
[Wenlin] http://www.wenlin.com
[Xu] Xu Zhimo’s poem http://ssb22.user.srcf.net/zhimo.html
[Yarowsky] http://www.cl.cam.ac.uk/teaching/1112/NLP/lectures.pdf pages 55–57
