








The C++ core guidelines are a useful summary of C++ best practice. Andreas Fertig shows their use.
In 2015 at CppCon, Bjarne Stroustrup announced the C++ Core Guidelines [ CCG ] in his opening keynote. These guidelines are a summary of best practices intended to overcome known traps and pitfalls of the C++ programming language. All the rules are grouped into several sections ranging from philosophy, interfaces and classes to performance and concurrency. The project is designed as an open source project, which should ensure that it will improve over time along with the language itself.
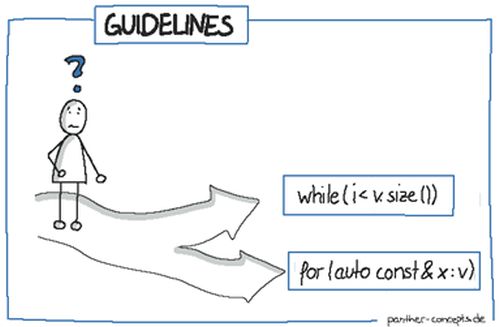
Behind this set of rules are some different ideas because, as Bjarne mentioned in his talk: “ We all hate coding rules ” [ Sommerlad16 ]. Often, the rules are written by people with weak experience with the particular programming language. They tend to keep the use of more complex features to a minimum, with the aim of preventing misuse by less experienced programmers. Both concepts are invalid for the Core Guidelines, which are written by experts in the field targeting programmers with C++ experience. The aim of the Core Guidelines is to assist people in using C++ effectively, which implies transitioning legacy C++ code towards modern C++, using C++11 or newer. The guidelines also focus on the language itself and using its power. For example, enable the use of static code analysis by expressing your intent in the language while leaving comments only for documentation. Consider this example:
int i = 0;
while( i < v.size() )
{
// do something with v[i]
}
By using modern C+, this can be transformed into something like this:
for(auto const& x: v)
{
// do something with x
}
(Example taken from [ Sommerlad16 ].)
There is a big difference between these two code fragments. In the first, a new variable comes into scope, and several problems can occur if it is reused. For example, it can lead to an out of bounds access Furthermore, there is the potential of getting the array access of
v
wrong by adding +1 to the loop variable. Tampering with this variable in other ways is also possible. These are typical mistakes, nothing somebody will do wrong on purpose. In the modern version, there is no need for an additional variable. It is also clear that the author is only interested in the objects of a vector. No modification will take place, hence the
const
reference. Since we are interested in all elements in the vector for the loop this is clearest. Last but not least, the modern version is much clearer to the compiler and static analysis tools. The compiler for instance, will not allow compilation if a write access to
x
takes place. A static analysis tool can understand that this is a way of iterating over the whole set of vector elements. You can improve it even more by using functions from
std::algorithm
like
std::replace
or
std::find
.
When using the C++ Core Guidelines, C++ becomes a little different. In Bjarne’s words: “ Within C++ is a smaller, simpler, safer language struggling to get out ” [ Stroustrup15 ]. This means that all the rules in the Core Guidelines work with a modern C++ compiler 1 . No additional extensions are required, albeit there are assisting libraries to facilitate using the rules. Let’s look at some of the rules.
Signalling failure
There is:
I.10: Use exceptions to signal a failure to perform a required task.
That’s a rule I struggle with. The standard library uses exceptions as the main failure signalling mechanism. It fully denotes the word ‘exception’. We do not expect such an event, so it’s reasonable to throw an exception at this point. This also leaves the return value for returning a value in case the function was successful. My struggle here is, if nobody expects something why should anyone catch it? A ball thrown at you unexpectedly can hurt a lot because you were not ready to catch it. Well, in case of C++, it’s like you are fast enough to duck. Then, at least you do not get hurt, but what about the others? You can let an exception which was caused by a function your code called pass to whoever called you. Now, the next higher function in the call stack has to deal with it. This pattern can continue until we hit
main
. Then, the program will terminate. Let’s say somebody within the call stack
does
catch the exception – now what? There is often no good choice. In the layers above, nobody knows which call triggered the exception and how to react to it. A horrible scenario for embedded systems which are somewhat critical! There may be millions of lines of code out there which can throw an exception, but I prefer not to. I use my freedom to
not
pick this rule for me.
What can we do instead? A solution I have come across multiple times is the following
int SomeFunction(int param1, double param2,
int* outValue)
{
//...
}
Let us suppose the returned value uses the full range of its data type; then, there is no space left to squeeze in the error code. Now, the choice is either to return the error code and pass the actual return value into the function as a pointer or reference parameter, or vice versa. Both are suboptimal.
The guidelines provide an alternative in section I.10: “ using a style that returns a pair of values ”.
auto [val, error_code] = do_something();
if (error_code == 0)
{
// ... handle the error condition
}
// ... use val
It uses structured bindings which are available in C++17. This allows us to return a struct and directly assign variables to the members. The resulting code is much clearer and robust compared to the variant shown before.
However, there is another alternative:
std::optional
(see Listing 1).
std::optional<std::string> GetUserName(int uid)
{
if( uid == 0 )
{
return "root";
}
return {};
}
void UsingOptional()
{
if( auto str = GetUserName(0) )
{
std::cout << *str << "\n";
}
auto fail = GetUserName(1);
std::cout << fail.value_or("unknown") << "\n";
}
|
| Listing 1 |
We can ask the optional object whether or not it contains a value, meaning it can be used in a boolean expression. In case you would like to skip all those checks, you can invoke it with
value_or()
and pass a value which is used when the object does not contain a valid object. Pretty neat.
Safe and modern array passing
Let’s move on to another item:
I.13: Do not pass an array as a single pointer.
This aims to solve a popular problem we can often see in the wild. For example, in the safe version of string copy:
char* strncpy(char* dst, const char* src,
size_t n)
{
// ...
}
Wow, how safe is that? We have a single
size_t
parameter. To which value does it apply? Alright, it enables us to write code like this:
strncpy( dst, src, MIN(dstSize, srcSize) );
Honestly, does this code look good to you? Writing
MIN()
over and over again? How many mistakes can still be made? Rule I.13 is about getting rid of code like this. Instead, there is the template class
span
which uses the power of templates to deduce the size of the object. You can also cut it down to just a slice of the array. The resulting object can be queried for its size, hence the chances for discrepancies are reduced by a lot. It is one object containing data and size. An improved string copy function would look like this:
span<char> strcpy(span<char> dst,
span<const char> src)
{
// ...
}
If you pay close attention, you will notice that we no longer need to check for null pointers in
strcpy
.
No raw pointers
Another rule is
R.10: Avoid
malloc()
and
free()
.
Together with
R.11: Avoid calling
new
and
delete
explicitly
it aims to reduce the use of uncontrolled memory allocation, with the goal of preventing memory leaks. In C++ with objects,
malloc
and
free
do nothing good for us. They are legacies from C. The guideline tells us to avoid
new
and
delete
in their naked form as well. In modern C++, the use of so called raw pointers, pointers without an owner, are discouraged. To handle resource management better, allocated memory should belong to an owner: some object which takes care of the lifetime of the memory. In modern C++, we have several kinds of managing pointers:
unique_ptr
,
shared_ptr
and
weak_ptr
. Helper functions like
make_unique
are available to assist us create such a pointer without writing
new
ourselves. Afterwards, the smart pointers take care of the allocated owned memory.
In case none of those managing pointers matches your needs, fallback to
owner<T>
. The idea behind it is to state the ownership of a simple pointer. In a perfect world, all
owner<T>
instances would be a managing a pointer like
unique_ptr
. When we are not there,
owner<T>
can be helpful for static analysis. Pointers which are not owning must not free memory. On the other hand, owning functions must free memory as soon as they go out of scope.
A library for the guidelines
For the best support of the C++ Core Guidelines, there is a library called ‘Guideline Support Library’ (GSL). Microsoft provides an implementation of it under the MIT licence hosted in github [ Microsoft ]. The concept of the library is to provide ready-to-use functions which enforce the idea of the C++ Core Guidelines, and increase the safety and correctness of a program.
There are simple things in it like
at()
. This tiny template function provides a bound-checked way of accessing built-in arrays like char buffer[1024].There are also places for things we did wrong for a long time:
narrow_cast
; again a template function which mimics the style of a C++ cast. Under the hood it checks whether the narrowing will lose signedness or results in a different value. Many of the checks are run-time checks. However, it is a way of letting static analysers know what you intend to do, and in doing so, there is a chance finding bugs before run-time.
In many ways, the GSL is similar to the boost [
Boost
] library. For years, boost has driven some new ideas and language improvements by letting the community try it out and decide if an idea is useful, all without compiler or standards changes. Some improvements of boost have found their way into recent C++ standards. The GSL may do the same for the community. In fact, they managed to get the first item of the GSL into the shiny new C++ standard C++17:
std::byte
[
C++
].
Summary
In summary, the C++ Core Guidelines try to encourage using modern C++. There is word on the street that they contain too many rules which at some point overlap. Still, they are a comprehensive collection of possible mistakes which can be avoided. Consider looking at the C++ Core Guidelines for ideas of how to write modern C++ and, of course, pick the items you consider valuable for your project. Also have a look at the GSL (multiple implementations are available) as it helps you write safer and more robust code.
Acknowledgements
Thanks to Peter Sommerlad who reviewed draft versions of this article. His comments contributed to substantial improvements to the article.
Artwork by Franziska Panter from panther concepts, https://panther-concepts.de
References
[Boost] http://www.boost.org/
[C++] http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0298r2.pdf
[CCG] https://github.com/isocpp/CppCoreGuidelines
[Microsoft] https://github.com/Microsoft/GSL
[Sommerlad16] http://wiki.hsr.ch/PeterSommerlad/files/ESE2016_core_guidelines.pdf
[Stroustrup15] https://github.com/CppCon/CppCon2015/blob/master/Keynotes/Writing%20Good%20C%2B%2B14/Writing%20Good%20C%2B%2B14%20-%20Bjarne%20Stroustrup%20-%20CppCon%202015.pdf
