








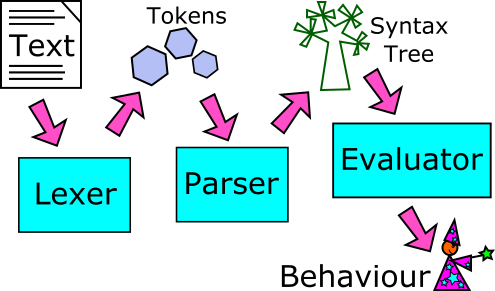
We’ve got our tokens: now we need to knit them together into trees. Andy Balaam continues writing a programming language with the parser.
In this series we are writing a programming language, which may sound advanced, but is actually much easier than you might expect. Last time, we wrote a lexer, which takes in text characters (source code) and spits out tokens, which are the raw chunks a program is made up of such as numbers, strings and symbols.
This time, we will write the parser, which takes the tokens coming out of the lexer and understands how they fit together, building structured objects corresponding to meaningful parts of our program, such as creating a variable or calling a function. These structured objects are called the syntax tree.
Next time, we’ll work on the evaluator, which takes in the syntax tree and does the things it says, executing the program. By the end of this series, you will have seen all the most fundamental parts of an interpreter, and be ready to build your own!
A bit more about Cell
Last time we saw that the language we are writing, Cell, is designed to be simple to write, rather than being particularly easy to use. It also lacks a lot of the error handling and other important features of a real language, but it does allow us to do the normal things we do when programming: make variables, define functions and perform logic and mathematical operations.
One of the ways Cell is simpler than other languages is that things like
if
and
for
that are normally special keywords in other languages are just normal functions in Cell. This program demonstrates this idea for
if
:
if(
is_even( 2 ),
{ print "Even!"; },
{ print "Odd."; }
);
In Cell,
if
is a function that takes three arguments: a condition, a function to call if the condition is true, and another to call otherwise (the
else
part). By passing functions as arguments, we avoid the need for a special keyword to define logical structures like
if
and
for
. This makes our parser simple, and it also means Cell programmers can write their own functions similar to the
if
function, and have them be first-class citizens, on a par to built-ins like
if
and
for
.
Because of the simplicity this allows, Cell’s parser only needs to recognise a few simple structures.
Cell’s parser

Cell has four expression types:
-
Assignment:
x = 3 -
Operations:
4 + y -
Function calls:
sqrt( -1 ) -
Function definitions:
{:(x, y) x + y;}
The parser’s job is to recognise from the tokens it sees which of these expression types it is seeing, and build up a tree structure of the expressions. For example, this code snippet:
x = 3 + 4;
should be parsed to a tree structure something like this:
Assignment:
Symbol: x
Value:
Operation:
Type: +
Arguments:
3
4
In Cell, you can tell what kind of expression you are looking at from the first two tokens. So in the example above, if we look at the first token ("
x
" we can’t tell whether this is going to be an operation like
x + 2
, or an assignment. Once we have the second token (
=
) we know we are dealing with an assignment.
Once the parser has recognised we are dealing with an assignment, it can treat everything on the right-hand side of the
=
as a new expression. This new expression will be parsed and nested inside the tree structure of the first one. That is how
Operation
ends up inside the
Assignment
section above.
Cell is written in Python, and the tree structures built up by the parser are Python tuples like (
"operation"
,
"+"
,
3
,
4
) or (
"assignment"
,
"x"
,
18
).
They can be nested inside each other like this:
("assignment",
"x",
("operation", "+", 3, 4)
)
which is the syntax tree representing the code
x = 3 + 4
.
Note: above we wrote
"x"
,
3
and
4
but in the actual syntax tree these will be full lexer tokens like (
"symbol"
,
"x"
) and (
"number"
,
"3"
).
Enough introduction – let’s get into the code.
The parse() function
Listing 1 shows the
parse()
function. Its job is to create a
Parser
object and call its
next_expression
method repeatedly until we have processed all the tokens coming from the lexer. It uses the
PeekableStream
stream class that we saw in the previous article to create a stream of tokens that we can ‘peek’ ahead into to see the next token that is coming.
def parse(tokens_iterator):
parser = Parser(PeekableStream(tokens_iterator),
";")
while parser.tokens.next is not None:
p = parser.next_expression(None)
if p is not None:
yield p
parser.tokens.move_next()
|
| Listing 1 |
When we create the Parser object, we pass two objects in to its constructor: the stream of tokens, and
";"
, which tells the parser when to stop. Here we end when we hit a semi-colon because we are parsing whole statements, and all statements in Cell end with a semi-colon. Later we will make other
Parser
objects that stop parsing when they hit other types of token like
","
and
")"
.
The Parser class
Listing 2 shows the constructor of
Parser
, which just remembers the stream of tokens we are operating on and
stop_at
, the token type that tells us we have finished.
class Parser:
def __init__(self, tokens, stop_at):
self.tokens = tokens
self.stop_at = stop_at
|
| Listing 2 |
Listing 3 shows the real heart of the parser – the
next_expression
method of the
Parser
object. Similar to the
lex()
function we saw in the previous article, the
next_expression
method is built around a big
if
/
elif
block.
def next_expression(self, prev):
self.fail_if_at_end(";")
typ, value = self.tokens.next
if typ in self.stop_at:
return prev
self.tokens.move_next()
if typ in ("number", "string", "symbol") and prev is None:
return self.next_expression((typ, value))
elif typ == "operation":
nxt = self.next_expression(None)
return self.next_expression(("operation", value, prev, nxt))
elif typ == "(":
args = self.multiple_expressions(",", ")")
return self.next_expression(("call", prev, args))
elif typ == "{":
params = self.parameters_list()
body = self.multiple_expressions(";", "}")
return self.next_expression(("function", params, body))
elif typ == "=":
if prev[0] != "symbol":
raise Exception("You can only assign to a symbol.")
nxt = self.next_expression(None)
return self.next_expression(("assignment", prev, nxt))
else:
raise Exception("Unexpected token: " + str((typ, value)))
|
| Listing 3 |
next_expression
takes one argument,
prev
, that represents the progress we have made parsing so far. Earlier we found that we only need to see the first two tokens of an expression to know what type it is. By passing the previous expression in to
next_expression
, we can use it, along with the current token, to understand what kind of expression we have. If we’re just starting to parse an expression, we pass in
None
as the value for
prev
.
Several of the branches of
next_expression
call
next_expression
from inside itself – this is because we are building up a nested tree of expressions within expressions. Every time we look for a sub-expression within an expression (for example the
"3 + 4"
part of
"x = 3 + 4"
) we call
next_expression
again, and use the return value as part of the original expression we are constructing.
Before we enter the big
if
/
elif
block,
next_expression
has an introductory section in which we get hold of the type and value of the next token we are dealing with, and stop parsing if we have hit one of the
stop_at
types. Since we were passed the expression so far in the
prev
argument, when we hit a
stop_at
token, we can immediately return it.
If we haven’t finished, we enter the
if
/
elif
block that checks the type of the token we are processing and returns an expression of the right type.
First, we check what to do if we see a normal type (string, number or symbol) and we have no previous expression (because
prev
is
None
). This means we have only seen one token so far, so we can’t decide what type of expression we are dealing with. To avoid making the decision yet, we call ourselves recursively, using
(typ, value)
– the token we were given – as the value for
prev
. This time we will have a non-
None
value for
prev
(because we just passed it in), and so will be able to make a decision about the expression we are parsing.
Next we check whether
typ
is
"operation"
. If it is, we are nearly ready to return an
"operation"
syntax tree. We have been given the left-hand side of the operation as
prev
, we’ve just found the operation, so all we need is the right-hand side to complete the expression. We call
next_expression
one more time, passing in
None
as the previous expression, because we want to find a separate expression to use at the right-hand side, and put the answer into a variable called
nxt
. Now we combine
nxt
with the information we already have, then return a tuple representing the whole operation:
("operation", value, prev, nxt)
. This is our syntax tree for this expression.
The next
elif
part checks for
"("
, which means we are calling a function. The
prev
variable should already contain the name of the function, so we just need to find the arguments we want to pass in. To find the arguments, we call
self.multiple_expressions
, which is shown in listing 4. Once we have the arguments, we can build a syntax tree of type
"call"
and pass it on into another call to
next_expression
..
def multiple_expressions(self, sep, end):
ret = []
self.fail_if_at_end(end)
typ = self.tokens.next[0]
if typ == end:
self.tokens.move_next()
else:
arg_parser = Parser(self.tokens, (sep, end))
while typ != end:
p = arg_parser.next_expression(None)
if p is not None:
ret.append(p)
typ = self.tokens.next[0]
self.tokens.move_next()
self.fail_if_at_end(end)
return ret
|
| Listing 4 |
By calling
next_expression
again, we allow multiple function calls to be stuck together, allowing us to write functions that return other functions and call them immediately. For example,
divide_by(3)(12);
might return
4
, because
divide_by(3)
could return a function that divides whatever you pass in by 3.
The
multiple_expressions
method parses several expressions separated by tokens of the type we provided (
"sep"
) and finishing when we get to another token (
"end"
). In the example we have seen so far, the separator was
","
and the end token was
")"
because we are looking for the arguments being passed to a function.
The code of
multiple_expressions
itself creates a new instance of the
Parser
class for every expression it looks for, telling it to stop when it hits the separator or the end, and stops looking when it hits the end.
Switching back to the big
if
/
elif
block from listing 3, the last two significant parts check for
"{"
and
"="
tokens.
"{"
means we are defining a function, so we use
multiple_expressions
again to find the statements inside the function, and to find the names of the arguments, it uses the
parameters_list
function, which is like a simplified version of
multiple_expressions
that just looks for the names of the arguments to the function (we skip it here for brevity).
The
"="
sign means we are defining a variable, which is quite simple – we just check that the previous token was a symbol, and then make an
"assignment"
syntax tree with that symbol and whatever is on the right-hand side.
If we get to the
else
part, we have encountered tokens in an order we can’t recognise, and we raise an exception, which prints a (very unfriendly) error for the user.
If you’ve managed to follow so far, you have seen all the interesting parts of Cell’s parser – why not try adapting it or writing your own language that works the way you want it to?
A note on operator precedence
If you were watching closely, you might have noticed one of the quirks of Cell’s parser that makes it different from most similar-looking languages: the order in which expressions are grouped when they contain multiple terms.
Most languages follow rules inspired by mathematical expressions, so that e.g. multiplications are grouped together before additions, meaning
"3*4+1"
evaluates to 12.
Cell is different. Because we parse ‘everything else’ and use it as the right-hand side in the operation, we group things on the right before things on the left, and we treat all operators the same, so
3*4+1
evaluates to 15.
Cell works this way because it means we have to write less code, but doing things the more normal way would be perfectly possible – we simply need to collect the full list of chained expressions before we start grouping them according to some precedence rules.
Summary
Parsing is an odd programming task, because we want to handle it piece by piece, but we sometimes need to soak up several tokens before we know what we are dealing with, and we need to produce a nested structure as our output. By using recursion (calling
next_expression
from inside itself) we can get the nested structure almost for free.
The code we looked at here is more complicated than the lexer we saw in the last article, but I think you’ll agree there is no magic here. The whole of Cell’s parser is just 81 lines of code (including empty lines). You can find it on Cell’s GitHub site [ Balaam ] along with more explanations (including some videos).
While Cell’s parser does work for a real, working language (if a toy one), it is a very simple example, and there is a huge amount you can learn about different types of parser, as well as tools that automatically build the code of a parser from some higher-level description of the language. A good place to start is the Wikipedia page ‘Parsing’ [ Wikipedia ].
You can find the whole source code for Cell on Github [ Balaam ], along with articles and videos explaining more about how it works.
Next time, we’ll get to the real point: we’ll look at the evaluator, which takes in the nice structured syntax tree produced by the parser and actually does things, turning our code into behaviour.
References
[Balaam] https://github.com/andybalaam/cell
[Wikipedia] ‘Parsing’, https://en.wikipedia.org/wiki/Parsing
