








Logging can be a bottleneck in systems. Wesley Maness and Richard Reich demonstrate a low-latency logging framework that avoids common problems.
If anybody wants to build highly scalable systems, I recommend you study logging systems and then do completely the opposite. You got some hope of making a scalable system or high performance system at that stage.
Martin Thompson in
Designing for Performance
. [
Thompson16
]
With that in mind we hope the idea proposed in this article is an exception to Martin’s observation.
We wish to utilize some of our findings related to cache-line awareness in a previous publication [ Maness18 ] to solve a more practical real world problem often encountered by many developers: a low latency logging frame work (LLLF). What is an LLLF? One could ask five software engineers and probably get ten different answers. The same question about the concept of low latency can have numerous definitions and ranges as well as acceptable deterministic behaviors. Before we get into absolute measurements, we can instead focus on the basic concepts of an LLLF. In general, an LLLF could be thought of as a framework that allows you to capture a minimally complete set of information at run time in a path of execution. This path of execution is often referred to as a hot path or critical path. Ideally this path of execution has the properties of being as fast as possible and deterministic. The goal of the critical path is to execute business logic while at the same time capturing data about the state of business logic at important points in the execution.
One of the more common building blocks for achieving concurrent execution is a ring buffer. In our case, we are separating critical and non-critical paths of execution. The ring-buffer is a general purpose tool, which can be customized for many different use-cases. In this article, the use-case will be the LLLF. We will pay special attention to the entry into the ring-buffer, or the produce method; this is where the focus of our analysis will take place as this could potentially be the major bottleneck in the performance of the critical path. Delivering information from one thread to another is one of the fundamental operations of concurrent execution. Doing so with low latency, high determinism is paramount in an LLLF. Later, in the code section of the paper, we provide a complete source code listing of the ring buffer utilized in all analyses.
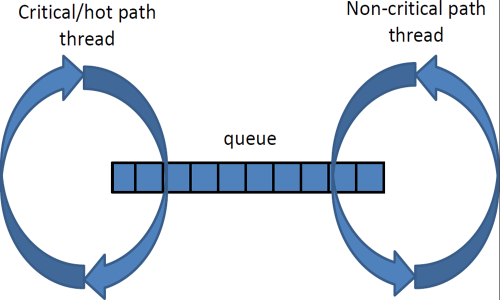
Once the state has been captured in the critical path of your process, it must be efficiently stored in memory for another thread and/or process to serialize the information to be archived. This could be in a human-readable format or in binary (and another process could perform the binary to human-readable conversion later). There are numerous ways in which information is passed from the thread that is executing the fast path to a secondary process and/or thread performing the serialized output as shown in Figure 1. The critical path LLLF could write into shared memory, memory, messaging infrastructure, or some shared queue. Once written to the transport medium the LLLF in the critical path would then need to notify or inform the secondary process to process the written information and write to disk. The notification is often handled by the form of an atomic increment, but there are other techniques to relay this information. The process writing to disk could have a busy loop checking the atomic variable and simply notices the value has increased and will process that information from the transport medium and serialize to disk. These are the basic building blocks of a LLLF.
|
| Figure 1 |
Intel intrinsics [
Intel
] are used in this article as a way of executing Intel specific instructions. The first
_mm_prefetch
is used to load the first part of logging memory upon initialization and helps with performance at the 95th percentile and above. The second,
_mm_clflush
, is used at initialization to push all the logging memory out of the cache hierarchy to leave as much of the cache free as possible; this is a serializing instruction and is well suited for initialization purposes. Lastly
_mm_clflushopt
is used to clear populated cache lines when the consumer thread has completed its usage of the cache lines.
Definitions
In this article, the parts in an LLLF that we want to address are cache-line awareness, cache pollution and memory ordering. We will focus on optimizing the critical path’s insertion of minimally complete information into some shared queue, for generating a log of operations. We need to first define some core concepts in our design and their potential impact on our LLLF. Cache-line awareness was addressed in our first article [ Maness18 ].
-
Cache pollution – Occupying space in the cache when not necessary.
- When accessing or creating data that will not be used in an amount of time that it will reasonably exist in the cache. The data is evicted due to other activity before it is accessed again.
- When accessing data that will not be accessed again, such as data that has been sent over the network.
- When accessing large amounts of data that will only be used once.
- Memory ordering – Memory ordering is vital for the creation of critical sections to ensure state is maintained between concurrent threads. More information can be found in the reference here [ CPP ].
- Explicit atomics – when using non-default memory ordering in C++ atomic operations, careful attention must be applied to their use. However, in some cases, significant performance gains can be realized.
- CPU pipeline – The process of executing many instructions independently of each other and discarding results that have dependencies.
- Structure.
In Figure 1, we illustrate a very common approach to logging in low latency environments and it is the same approach we have taken for our work in this article. Both the critical path and the non-critical path are generally spinning threads. Each thread is pinned to a different core, and the cores do not necessarily need to be on the same NUMA node. There was no performance difference in the critical path if the logging thread was on another NUMA node. The queue can exist in memory, shared memory or perhaps NVDIMM.
The critical path is the path of execution that must carry out a series of well-defined operations under very specific performance criteria. These metrics are often measured in terms of latency or CPU cycles under various percentiles. For example, you would want to know how many microseconds it would take to execute a complete cycle in the critical path, or some segment of the critical path, at the 99th percentile. This measured time also includes the time it takes to place a work item onto the queue for later consumption by the non-critical thread. The work item should be a minimally complete set of information necessary to capture state at that spot in the critical path.
The non-critical thread is spinning and once it can determine there is a work item in the queue for consumption, it pops the work item off the queue, does any mappings or lookups in needs to perform, translates the work item into some human readable format and serializes to a destination, often to disk based storage.
Code
Listing 1 takes the ring buffer as an argument and casts the data to the payload type defined using the parameter pack type. This is not intended for production use, but simply demonstrate functionality.
using TimeStamp_t = uint64_t;
template <template<typename> typename A,
typename... Args>
uint64_t writeLog (RingBuff& srb)
{
using Payload_t = Payload<Args...>;
A<Args...> arch;
Payload_t *a =
reinterpret_cast<Payload_t*>(
srb.pickConsume(sizeof(Payload_t)));
if (a == nullptr )
return 0;
// detect empty parameter pack
if constexpr(sizeof...(Args) != 0)
{
arch.seralize(a->data);
// properly deconstruct, may have
// complex objects
a->~Payload_t();
memset((char*)a, 0, sizeof(Payload_t));
srb.consume(sizeof(Payload_t));
}
return sizeof(Payload_t);
}
|
| Listing 1 |
The snippet below shows a type that extracts underlying types from the r-value. The
NR
in
TupleNR
means no reference.
template <typename... T>
using TupleNR_t = std::tuple
<typename std::decay<T>::type...>;
Listing 2 is the structure that is created in the ring buffer. It contains the function pointer to the method containing the parameter pack type. It is aligned to the pointer size.
template <typename... Args>
struct alignas(sizeof(void*)) Payload
{
using Func_t = uint64_t (*)(RingBuff&);
Payload(Func_t f, Args&&... args)
: func_(f)
, data(args...)
{
// all of this washes away at compile time.
auto triv_obj = [](auto a)
{
static_assert(
std::is_trivially_default_constructible
<decltype(a)>::value,
"Trivial Default Ctor required");
static_assert(
std::is_trivially_constructible
<decltype(a)>::value,
"Trivial Ctor required");
static_assert(std::is_trivially_destructible
<decltype(a)>::value,
"Trivial Dtor required");
};
std::apply([triv_obj](auto&&... a)
{((triv_obj(a), ...));}, data);
}
Func_t func_;
TupleNR_t<Args...> data;
};
|
| Listing 2 |
Listing 3 simply constructs the payload using placement new within the ring buffer. It is worth pointing out that the code here will drop payloads that are newest in the queue, not the oldest ones. We chose this approach as it is often a requirement in financial systems to prioritize retaining older log messages over newer ones. This is because of certain regional regulatory requirements (although all should be captured and saved off). We could construct a drop policy where we can specify which to drop, older or newer payloads, and measure each policy’s impact on performance (not shown here).
template <typename... Args>
uint64_t userLog (Args&&... args)
{
auto timeStamp = __rdtsc();
using Payload_t = Payload<TimeStamp_t, Args...>;
char* mem = data.pickProduce(sizeof(Payload_t));
if (mem == nullptr)
{
++logMiss_;
return 0;
}
// The beauty of placement new!
// A simple structure is created and memory is
// reused as ring buffer progresses
[[maybe_unused]]Payload_t* a = new(mem)
Payload_t(
writeLog<TimeStamp_t, Args...>
, std::forward<TimeStamp_t>(timeStamp)
, std::forward<Args>(args)...);
data.produce(sizeof(Payload_t));
// Consider RIAA
data.cleanUpProduce();
return timeStamp;
}
|
| Listing 3 |
Listing 4 shows the ring buffer in its entirety.
#pragma once
#include <iostream>
#include <atomic>
#include <emmintrin.h>
#include <immintrin.h>
#include <x86intrin.h>
constexpr uint64_t cacheLine = 64;
constexpr uint64_t cacheLineMask = 63;
class RingBuff
{
public:
using RingBuff_t = std::unique_ptr<char[]>;
private:
const int32_t ringBuffSize_{0};
const int32_t ringBuffMask_{0};
const int32_t ringBuffOverflow_{1024};
RingBuff_t ringBuff0_;
char* const ringBuff_;
std::atomic<int32_t> atomicHead_{0};
int32_t head_{0};
int32_t lastFlushedHead_{0};
std::atomic<int32_t> atomicTail_{0};
int32_t tail_{0};
int32_t lastFlushedTail_{0};
public:
RingBuff() : RingBuff(1024) {}
RingBuff(uint32_t sz)
: ringBuffSize_(sz)
, ringBuffMask_(ringBuffSize_-1)
, ringBuff0_(new
char[ringBuffSize_+ringBuffOverflow_])
, ringBuff_{(char*)(((intptr_t)
(ringBuff0_.get()) + cacheLineMask) &
~(cacheLineMask))}
{
for ( int i = 0;
i < ringBuffSize_+ringBuffOverflow_;
++i)
memset( ringBuff_, 0,
ringBuffSize_+ringBuffOverflow_);
// eject log memory from cache
for ( int i = 0;
i <ringBuffSize_+ringBuffOverflow_;
i+= cacheLine)
_mm_clflush(ringBuff_+i);
// load first 100 cache lines into memory
for (int i = 0; i < 100; ++i)
_mm_prefetch( ringBuff_ + (i*cacheLine),
_MM_HINT_T0);
}
~RingBuff()
{
}
int32_t getHead( int32_t diff = 0 )
{ return (head_+diff) & ringBuffMask_; }
int32_t getTail( int32_t diff = 0 )
{ return (tail_+diff) & ringBuffMask_; }
char* pickProduce (int32_t sz = 0)
{
auto ft = atomicTail_.load(
std::memory_order_acquire);
return (head_ - ft > ringBuffSize_ -
(128+sz)) ? nullptr :
ringBuff_ + getHead();
}
char* pickConsume (int32_t sz = 0)
{
auto fh = atomicHead_.load(
std::memory_order_acquire);
return fh - (tail_+sz) < 1 ? nullptr :
ringBuff_ + getTail();
}
void produce ( uint32_t sz ) { head_ += sz; }
void consume ( uint32_t sz ) { tail_ += sz; }
uint32_t clfuCount{0};
void cleanUp(int32_t& last, int32_t offset)
{
auto lDiff = last - (last & cacheLineMask);
auto cDiff = offset -
(offset & cacheLineMask);
while (cDiff > lDiff)
{
_mm_clflushopt(ringBuff_ +
(lDiff & ringBuffMask_));
lDiff += cacheLine;
last = lDiff;
++clfuCount;
}
}
void cleanUpConsume()
{
cleanUp(lastFlushedTail_, tail_);
atomicTail_.store(tail_,
std::memory_order_release);
}
void cleanUpProduce()
{
cleanUp(lastFlushedHead_, head_);
// significant improvement to fat tails
_mm_prefetch(ringBuff_ +
getHead(cacheLine*12), _MM_HINT_T0);
atomicHead_.store(head_,
std::memory_order_release);
}
char* get() { return ringBuff_; }
};
|
| Listing 4 |
Results
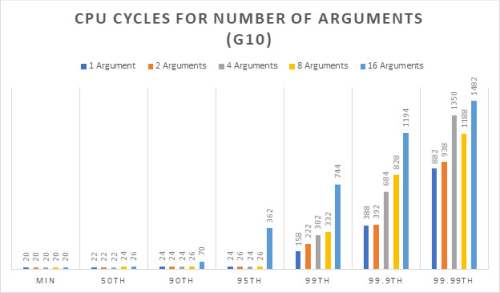
The graph shown in Figure 2 captures the number of cycles it takes to push the number of arguments (each argument is an 8-byte integer) into the ring buffer for the percentiles shown for the G10 machine. Specifications for the G10 are shown in the references section.
|
| Figure 2 |
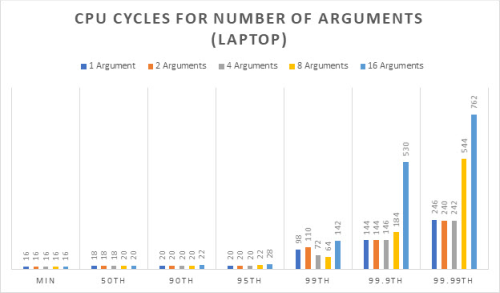
The graph in Figure 3 captures the number of cycles it takes to push the number of arguments into the ring buffer for the percentiles shown for the Linux laptop machine in the references section.
|
| Figure 3 |
Clearly the benefits of a more modern architecture are shown. For example, comparing G10 to the personal laptop at 99.99th percentile, the number of cycles for 16 arguments was more than cut in half from 1132 to 576. Both systems are locked at 3GHz with CPU and IRQ isolation.
Conclusions/Summary
If you do not have access to the CLFLUSHOPT [ Intel19a ] [ Intel19b ] calls, please contact us so that we can provide an auxiliary path implementation with compiler options, which we have not shown here.
Another point to make, that isn’t shown here, is that if we didn’t utilize the CLFLUSHOPT calls to minimize the cache pollution, we observed (in production code) much higher latencies, at 90th percentile and above. We observed no noticeable improvements in latency due to CLFLUSHOPT in micro benchmarking. It’s important to note also that due to the test performances themselves, we noticed some numbers jumping around, most attributed to pipelining and branch prediction.
There are several logging frameworks [ GitHub-1 ] [ GitHub-2 ] that are open sourced and target the low latency crowd. We have decided not to compare them in this paper, but instead reference the loggers here and leave it as an exercise for the reader to do their own analysis and come to their own conclusions.
Acknowledgments
Special thanks to Frances and the review board of ACCU Overload .
References
[CPP] ‘Memory model’ on cppreference.com: https://en.cppreference.com/w/cpp/language/memory_model
[GitHub-1] ‘Super fast C++ logging library’, available at: https://github.com/KjellKod/spdlog
[Github-2] ‘G3log’, available at: https://github.com/KjellKod/g3log
[Intel] Intel Intrinsics Guide at https://software.intel.com/sites/landingpage/IntrinsicsGuide/
[Intel19a] Intel 64 and IA-32 Architectures Optimization Reference Manual , published April 2019 by the Intel Corporation, available at: https://software.intel.com/sites/default/files/managed/9e/bc/64-ia-32-architectures-optimization-manual.pdf
[Intel19b] Intel 64 and IA-32 Architectures Software Developer’s Manual , published May 2019 by Intel Corporation, available at: https://software.intel.com/sites/default/files/managed/39/c5/325462-sdm-vol-1-2abcd-3abcd.pdf
[Maness18] Wesley Maness and Richard Reich (2018) ‘Cache-Line Aware Data Structures’ in Overload 146, published August 2018, available at: https://accu.org/index.php/journals/2535
[Thompson16] Martin Thompson (2016) ‘Designing for Performance’ from the Devoxx conference, published to YouTube on 10 November 2016: https://youtu.be/03GsLxVdVzU
G10 specifications
https://h20195.www2.hpe.com/v2/getpdf.aspx/a00008180ENUS.pdf
GCC 7.1. was used on the G10 with the flags std+c++17 -Wall -O3. Dual socket 18 core (36 total) Intel ® Gold 6154 CPU @ 3GH. Hyper-threading was not enabled. CPU isolation is in place.
Laptop specifications
Gentoo with GCC 8.2
Linux localhost 4.19.27-gentoo-r1 #1 SMP Tue Mar 19 10:23:15 -00 2019 x86_64 Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz GenuineIntel GNU/Linux
has 25 years of experience in software engineering ranging from digital image processing/image recognition in the 90s to low latency protocol development over CAN bus in early 2000s. Beginning in 2006, he entered the financial industry and since has developed seven low latency trading platforms and related systems.
