








The minverse algorithm previously seen is fast but has limitations. Cassio Neri presents two alternatives.
The first instalment of this series [
Neri19
] introduced the
minverse
algorithm and a C++ library called
qmodular
[
qmodular
] that implements it. We have seen that in certain cases
minverse
performs better than the algorithm currently implemented by major compilers when evaluating expressions of the form
n % d == r
. Unfortunately,
minverse
does not work when
==
is replaced by
<
,
<=
,
>
or
>=
. This article presents two algorithms that do not have this restriction, namely,
Multiply and Shift
(
mshift
) and
Multiply and Compare
(
mcomp
). They are very similar to one another and also to the
Remainder by Multiplication and Shifting Right
(
RMSR
) covered in
Hacker’s Delight
[
Warren13
].
It is important to remember that the intention here is not to ‘beat’ the compiler. On the contrary, this series is an open letter addressed to compiler writers presenting some algorithms that, potentially, could be incorporated into their product for the benefit of all programmers. Performance analysis shows that the alternatives discussed in this series are often faster than built-in implementations.
Recall and warm up
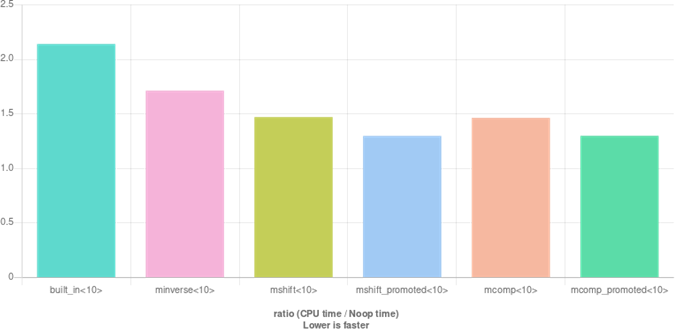
We start by looking at Figure 1
1
which displays the time taken to check whether each element of an array of 65,536 uniformly distributed unsigned 32-bit dividends in the interval [0, 10
6
] leaves remainder 3 when divided by 10. Bars
built_in
and
minverse
correspond to algorithms presented in [
Neri19
]. (
Built-in
is simply
2
n % 10 == 3
.) Bars
mshift
and
mcomp
refer to algorithms covered by this article. A simple variant of each,
mshift_promoted
and
mcomp_promoted
, are also shown.
|
| Figure 1 |
All measurements include the time to scan the array of dividends which is used as unit of time. Timings 3 are 2.14 for built-in , 1.71 for minverse , 1.47 for mshift and mcomp and 1.30 for promoted variants. Subtracting the scanning time and taking results relatively to built-in ’s yields 0.71/1.14 ≈ 0.62 for minverse , 0.47/1.14 ≈ 0.41 for mshift and mcomp and 0.30/1.14 ≈ 0.26 for promoted algorithms. These numbers, however, depend on the divisor as will be made clear later on.
Listing 1 contrasts the code generated by GCC 8.2.1 with
-O3
for some of these algorithms.
built_in 0: mov %edi,%eax 2: mov $0xcccccccd,%edx 7: mul %edx 9: shr $0x3,%edx c: lea (%rdx,%rdx,4),%eax f: add %eax,%eax 11: sub %eax,%edi 13: cmp $0x3,%edi 16: sete %al 19: retq minverse 0: sub $0x3,%edi 3: imul $0xcccccccd,%edi,%edi 9: ror %edi b: cmp $0x19999999,%edi 11: setbe %al 14: retq mshift 0: imul $0x1999999a,%edi,%edi 6: shr $0x1c,%edi 9: cmp $0x4,%edi c: sete %al f: retq mcomp 0: sub $0x3,%edi 3: imul $0x1999999a,%edi,%edi 9: cmp $0x1999999a,%edi f: setb %al 12: retq |
| Listing 1 |
Recall that we are concerned with the evaluation of modular expressions where the divisor is a compile time constant and the dividend is a runtime variable. The remainder can be either. They all have the same unsigned integer type which implements modulus 2 w arithmetic. (Typically, w = 32 or w = 64.) We focus on GCC 8.2.1 for an x86_64 target but some ideas here might also apply to other platforms.
The ‘Remainder by Multiplication and Shifting Right’ algorithm
This section loosely follows [ Warren13 ] and covers the basics of RMSR by means of an example. We shall see that RMSR , mshift and mcomp have the same underlying idea.
Let the divisor be
d
= 10. By Euclidean division, any integer
n
can be uniquely written as
n
= 10 ∙
q
+
r
, where
q
and
r
are integers,
r
∈ [0, 9]. Written in code,
q = n / 10
and
r = n % 10
. Using this expression we obtain
⌊16 ∙ ( n / 10)⌋ = ⌊16 ∙ ((10 ∙ q + r ) / 10)⌋ = ⌊16 ∙ q + (16 ∙ r ) / 10)⌋
= 16 ∙ q + ⌊16 ∙ ( r / 10)⌋.
It follows that ⌊16 ∙ ( n / 10)⌋ ≡ ⌊16 ∙ ( r / 10)⌋ (mod 16).
[ Warren13 ] observes that for r = 0, 1, 2, 3, 4, 5, 6, 7, 8 and 9, the quantity ⌊16 ∙ ( r / 10)⌋ takes values on 0, 1, 3, 4, 6, 8, 9, 11, 12 and 14, respectively. Since the latter numbers are all distinct they can be mapped back to the former. Therefore, we efficiently obtain r provided we can reasonably evaluate:
- ⌊16 ∙ (n / 10)⌋ mod 16; and
- the inverse of φ defined by φ ( r ) = ⌊16 ∙ ( r / 10)⌋, for all r ∈ {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}.
We consider the evaluation of ⌊16 ∙ ( n / 10)⌋ mod 16 by looking at the binary representation of intermediate results, namely, x 1 = n / 10, x 2 = 16 ∙ x 1 , x 3 = ⌊ x 2 ⌋ and x 4 = x 3 mod 16. To get x 2 we multiply x 1 by 16, which shifts bits 4 positions to the left. In particular, the first 4 bits of x 1 on the right of the binary point move to its left. To get x 3 , we apply the integer part function discarding fractional bits. Finally, to get x 4 we take modulo 16 zeroing all but the 4 leftmost bits. For example, for n = 98 we have (relevant bits are emphasised):
x 1 = 98 / 10 = 9.8 = (1001. 1100 1100…) 2 ,
x 2 = 16 ∙ x 1 = 156.8 = (1001 1100 .1100…) 2 ,
x 3 = ⌊ x 2 ⌋ = 156 = (1001 1100 ) 2 ,
x 4 = x3 mod 16 = 12 = ( 1100 ) 2 .
The ellipses above serve as reminders that those equalities hold in the beautiful world of infinite precision which our CPUs do not belong. Rounding is necessary and error is unavoidable. Caution is required to avoid trashing the bits that we are interested in. Hence, we look for an approximation of x 1 = n / 10 known to be correct at least up to 4 bits after the binary point or, equivalently, an approximation of x 2 = (2 4 / 10) ∙ n correct, at least, on its integer part. There is an efficient way to tackle this problem. It is a classical idea widely used by compilers to evaluate division by compile time constants. For the sake of concreteness, we restrained this discussion to 32-bit CPUs.
We have x 2 = (2 4 / 10) ∙ n = (2 32 / 10) ∙ n / 2 28 . Here the rounding comes: number (2 32 / 10) = 429,496,729.6 is rounded up to M = 429,496,730 ([ Warren13 ] rounds it down) and we get x 2 ≈ M ∙ n / 2 28 . The error of this approximation, ( M - (2 32 / 10)) ∙ n / 2 28 , grows with n and thus, for n large enough, it becomes such that x 2 and M ∙ n / 2 28 do not have the same integer part. For such values x 3 ≠ ⌊ M ∙ n / 2 28 ⌋ and the algorithm breaks. For instance, for n = 2 27 , we have x 2 = (2 4 / 10) ∙ 2 27 = 2 31 / 10 = 214,748,364.8 whereas M ∙ n / 2 28 = M ∙ 2 27 / 2 28 = M / 2 = 214,748,365.
Despite the last issue, there exist a maximal interval [0,
N
] such that
x
3
= ⌊
M
∙
n
/ 2
28
⌋ for any integer
n
∈ [0,
N
]. Finishing part 1 of the
RMSR
requires evaluating
x
4
=
x
3
mod 16. However, by yet another practical aspect of CPUs, this step becomes unnecessary. Indeed, ⌊
M
∙
n
/ 2
28
⌋ is evaluated as
(M * n) >> 28
in modulus 2
32
arithmetic. Hence all but the 32 leftmost bits of
M * n
are discarded. After the 28-bits right shift only the 4 leftmost bits of the result might be non-zero. Hence, the subsequent mod 16 operation has no effect.
The consideration for n = 2 27 above implies N < 2 27 . In particular, this method does not work on the whole range of 32-bit unsigned integers. [ Warren13 ] tackles this issue at the same time as he deals with the evaluation of φ -1 . (Part 2 of RMSR .) This is not straightforward and he covers it only for a handful of divisors. His approach uses bitwise tricks obtained, as he puts it, by ‘a lot of trial and error’ (which is not generic) and look-up tables (which does not scale well). Details can be seen in [ Warren13 ].
The mshift algorithm
Luckily, mshift and mcomp seek to make remainder comparisons without knowing it. For this reason they do not need to evaluate φ -1 and only take into consideration the fact that φ is strictly increasing.
We have seen that if
r
is the remainder of the division of
n
by 10, then ⌊16 ∙ (
n
/ 10) mod 16 =
φ
(
r
). Since
φ
is strictly increasing, we have
r
= 0 if, and only if,
φ
(
r
) =
φ
(0) = 0, ie, ⌊16 ∙ (
n
/ 10)⌋ mod 16 = 0. Therefore, the latter equality is equivalent to divisibility by 10. Finally, using the efficient evaluation of ⌊16 ∙ (
n
/ 10)⌋ mod 16, we get that for
n
∈ [0,
N
],
n % 10 == 0
is equivalent to
(M * n) >> 28 == 0
. The same applies to, say,
r
= 3: if
n
∈ [0,
N
], then
n % 10 == 3
if, and only if,
(M * n) >> 28 == (M * 3) >> 28
. (This is
mshift
in Figure 1 and Listing 1.)
Summarising, let
uint_t
be an unsigned integer type with modulus 2
w
arithmetic. Given any integer
d
∈ [2, 2
w
[, let
p
be the smallest integer such that
d
≤ 2
p
. Set
M
= ⌈2
w
/
d
⌉ and
s
=
w
-
p
. Then, there exists an integer
N
∈ [0, 2
w
[ such that for integers
n
∈ [0,
N
],
r
∈ [0,
d
- 1] and any relational operator ⋚ (i.e., ⋚ is any of
==
,
!=
,
<
,
<=
,
>
or
>=
), we have
n % d
⋚
r
is equivalent to
phi(n)
⋚
phi(r)
, where
phi
is defined by
uint_t phi(uint_t n) {
return (M * n) >> s;
}
A lower bound for
N
is straightforward to calculate but its derivation is outside the scope of this article. (See [
qmodular
].) Most often, we have
N
< 2
w
- 1 and, consequently,
mshift
cannot be applied to the whole range of
uint_t
. We shall see later how to deal with this limitation.
The mcomp algorithm
The underlying idea of
mcomp
is similar to
mshift
’s, the difference being a simple observation. The essential point of
mshift
is looking at a few bits of
n
/
d
after the binary point which are obtained through
phi
. This function introduces a rounding error that grows with
n
and, eventually, gets large enough to trash the important bits. At this point
phi
returns a wrong value and
mshift
breaks. Looking at more bits on the right of the binary point enables
mcomp
to carry on.
Consider the example d = 10 again. As in mshift , the first step of mcomp is evaluating the approximation ⌈2 32 / 10⌉ ∙ n , of (2 32 / 10) ∙ n , under modulus 2 32 arithmetic. Table 1 shows both products, in binary, for a few values of n . For ease of presentation, it only shows the most and least significant bytes of the 32 bits on the left of the binary point (ellipses account for the other 16 bits). (The 4 bits that are important to mshift are emphasised.)
|
|||||||||||||||||||||||||||||||||||||||||||||
| Table 1 |
When n divides 10 the second column shows 0 since (2 32 / 10) ∙ n is a multiple of 2 32 . The third column only approximates the second one: it starts showing 0, for n = 0, and steadily diverges from this value as n increases. Indeed, from n to n + 10 the error goes up by 4 (or (100) 2 ). (This is due to ⌈2 32 / 10⌉ ∙ 10 - (2 32 / 10) ∙ 10 = ⌈2 32 / 10⌉ ∙ 10 - 2 32 = 4.) Therefore, starting at 0, after 2 26 steps the error accrues to 4 ∙ 2 26 = 2 28 for n = 10 ∙ 2 26 . This is large enough to trash the 4 leftmost bits of M ∙ n , which become (0001) 2 . Notice the latter is the bit pattern expected for remainder r = 1 and not for r = 0 and then, mshift breaks at this point.
However, looking at all bits of the result, (0001 0000 … 0000 0000)
2
, we realise it is still far below (0001 1001 … 1001 1010)
2
which is the result for
n
= 1, that is,
M
= ⌈2
32
/ 10⌉ ∙ 1 = ⌈2
32
/ 10⌉. Therefore, if that
n
is not large enough for
M
∙
n
to reach the barrier
M
, then it is still possible to detect that
n
is a multiple of 10. In other words,
n % 10 == 0
is equivalent to
M * n < M
.
In general, for any remainder
r
∈ [0,
d
- 1], the result of
M
∙
n
mod 2
32
starts, for
n
=
r
, with a small error with respect to (2
32
/ 10) ∙
r
. The error steadily increases in steps of size 4 as
n
takes successive values with the same remainder. If
n
is not large enough for
M
∙
n
to reach the next barrier,
M
∙ (
r
+ 1), then it is still possible to detect that
n
has remainder
r
. This means that
n % 10 == r
is equivalent to
(M * r <= M * n) && (M * n < M * (r + 1))
. Well, this is not entirely true and some details must be considered.
For
r
= 9, we have
M
∙ (
r
+ 1) =
M
∙ 10 = 2
32
+ 4 ≥ 2
32
. Hence, regardless of
n
, the second operand of
&&
above should be
true
. Nevertheless, its evaluation can yield
false
since
M
∙ (
r
+ 1) overflows under modulus 2
32
arithmetic. To get the right result when
r
= 9, we should test only the left hand side of
&&
above.
Regarding
&&
, this operator creates a branch that can immensely degrade performance. To address this issue, notice that by subtracting
M
∙
r
from
M
∙
r
≤
M
∙
n
<
M
∙ (
r
+ 1) we get that these inequalities are equivalent to 0 ≤
M
∙ (
n
-
r
) <
M
. However, under modulus 2
32
arithmetic, the subtraction overflows when
n
<
r
. Although the correct derivation in modulus 2
32
arithmetic is not that straightforward, the previous result remains valid. Furthermore, 0 ≤
M
∙ (
n
-
r
) is always true and then, we can evaluate
n % 10 == r
as
M * (n - r) < M
, except when
r
= 9. In this case, the upper bound
M
should be replaced by
M - 4
to account for the fact that
M * 10
overflows by an excess of
4
.
There are outstanding issues to be addressed but we evasively refer to [ qmodular ] for details.
We now summarise the
mcomp
algorithm. Let
uint_t
be an unsigned integer type with modulus 2
w
arithmetic. Given any integer
d
∈ [2, 2
w
[, set
M
= ⌈2
w
/
d
⌉ and
m
=
M
∙
d
- 2
w
. If
m
<
M
, then there exists an integer
N
∈ [0, 2
w
[ such that for all integers
n
∈ [0,
N
] and
r
∈ [0,
d
- 1], we have:
-
n % d == ris equivalent to-
M * (n - r) < M, if r ≠ d - 1; -
M * (n - r) < M – m, if r = d - 1; -
M * n >= M * r, if r = d - 1;
-
-
n % d < ris equivalent toM * n < M * r.
From these results we can derive similar equivalences for other relational operators.
The unbounded case
Like minverse , r ∈ [0, d - 1] is a precondition for mshift and mcomp . To extend these algorithms to larger remainders, the same approach used for minverse can be applied. (See [ Neri19 ].)
Increasing the range of applicability
Both mshift and mcomp have a range of applicability, (expressed by the hypothesis n ∈ [0, N ]) which, most often, is not the whole domain of the unsigned integer types they work on. (In contrast, built-in and minverse do not have this limitation.)
An easy way of increasing these algorithm’s applicability is by promoting the type that they work on. Specifically, to evaluate a modular expression with
uint32_t
operands, we can promoted
n
,
d
and
r
to
uint64_t
and use the algorithm for this type. This is what the suffix
_promoted
in Figure 1 refers to.
Although GCC provides 128-bit unsigned integer types, on x86_64 platforms these types only have partial support from the CPU and must be synthesised by software. Therefore, the promotion strategy might be rather expensive for
uint64_t
and using
mshift
or
mcomp
for this type of operand might not be the best option if performance and full range of applicability are simultaneously needed.
Performance analysis
As in the warm up, all measurements shown in this section concern the evaluation of modular expressions for 65,536 uniformly distributed unsigned 32-bit dividends in the interval [0, 10 6 ]. Remainders can be either fixed at compile time or variable at runtime. Charts show divisors on the x -axis and time measurements, in nanoseconds, on the y -axis. Timings are adjusted to account for the time of array scanning.
For clarity we restrict divisors to [1, 50] which suffices to spot trends. (Results for divisors up to 1,000 are available in [ qmodular ].) In addition, we filter out divisors that are powers of two since the bitwise trick is undoubtedly the best algorithm for them. The timings were obtained with the help of Google Benchmark [ Google ] running on an AMD Ryzen 7 1800X Eight-Core Processor @ 3600Mhz; caches: L1 Data 32K (x8), L1 Instruction 64K (x8), L2 Unified 512K (x8), L3 Unified 8192K (x2).
Figure 2 concerns divisibility tests, that is, evaluation of
n % d == 0
. As already seen in [
Neri19
], built-in is slower than
minverse
which zigzags as divisors changes from odd (faster) to even (slower) values. The new algorithms,
mshift
and
mcomp
, perform for all divisors as good as
minverse
does for odd divisors. In contrast, their promoted variants perform better than
minverse
for even divisors. This makes the
minverse
preferable for odd divisors since it does not have the limitation on the range of
n
whereas either of the promoted variants is preferable for even divisors.
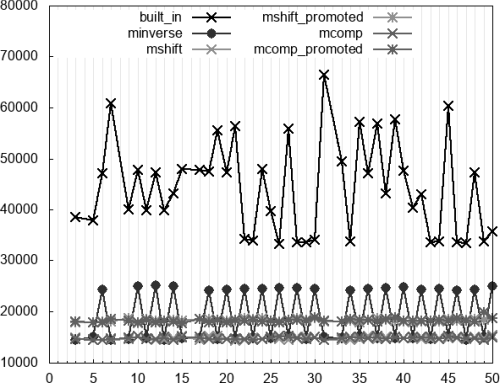
|
| Figure 2 |
Figure 3 covers
n % d == r
where
r
is variable and uniformly distributed in [0,
d
- 1]. In this example,
r < d
always holds true but the compiler does not know it and adds a precondition check before calling
mshift
,
mcomp
and their promoted variants. For clarity, we do not include
minverse
but it is worth remembering (see [
Neri19
]) that it is slower than the built-in algorithm except for the few divisors for which the latter spikes. More or less the same happens here for
mshift
and its promoted flavour. The good news is that both variations of
mcomp
are faster than the built-in algorithm.
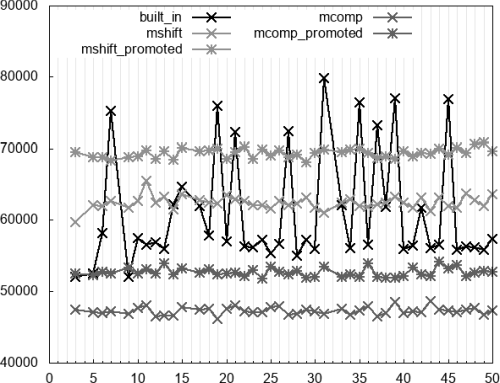
|
| Figure 3 |
Finally, Figure 4 considers the expression
n % d > 1
. (Recall that
minverse
cannot evaluate this expression.) The built-in algorithm performs worse than all others and the promoted variations perform worse than their regular counterparts.
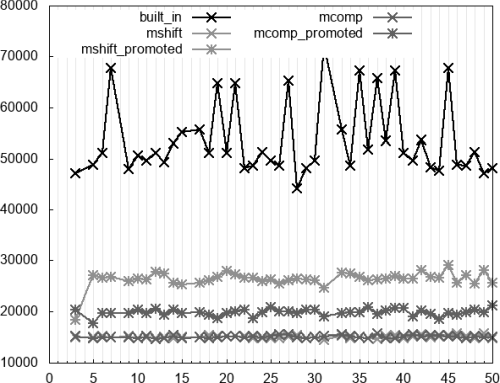
|
| Figure 4 |
Related work
As we have seen,
mshift
and
mcomp
follow the idea of
RMSR
as presented in [
Warren13
]. Furthermore, a recent work [
Lemire19
] presents a slight variation of promoted
mcomp
for
uint32_t
. However, [
Lemire19
] restricts its discussion and analysis to divisibility tests, that is, to expressions of the form
n % d == 0
.
Conclusion
This article presents the
mshift
and
mcomp
algorithms, which make remainder comparisons without knowing its value. In contrast to
minverse
, seen in the previous instalment of this series, they allow the usage of any comparison operator. However, they have a limitation not shared by
minverse
: in general, their range of applicability is not as large as the range of the inputs’ type. To address this issue, this article presents the promoted variants which take
uint32_t
inputs and make intermediate calculations on
uint64_t
values. We have seen situations where these algorithms can perform better than
minverse
and the built-in algorithm currently implemented by major compilers.
Although we have worked around the limitation on inputs by promoting
uint32_t
values to
uint64_t
, a similar idea is not viable when the input is already of the latter type. More precisely, there is no efficient promoted variant when inputs are already of type
uint64_t
. This is the greatest limitation of
mshift
and
mcomp
. In Part 3 of this series we shall see yet another algorithm that does not have this issue.
Acknowledgements
I am deeply thankful to Fabio Fernandes for the incredible advice he provided during the research phase of this project. I am equally grateful to the Overload team for helping improve the manuscript.
References
[Google] https://github.com/google/benchmark
[Lemire19] Daniel Lemire, Owen Kaser and Nathan Kurz, Faster Remainder by Direct Computation: Applications to Compilers and Software Libraries, Software: Practice and Experience 49 (6), 2019.
[Neri19] Cassio Neri, ‘Quick Modular Calculations (Part 1)’, Overload 154, pages 11–15, December 2019.
[qmodular] https://github.com/cassioneri/qmodular
[QuickBench] Quick C++ Benchmark: http://quick-bench.com/u3y2EZt_F8eAtWmFimt0MrwfHS8
[Warren13] Henry S. Warren, Jr., Hacker’s Delight , Second Edition, Addison Wesley, 2013.
- Powered by quick-bench.com . For readers who are C++ programmers and do not know this site, I strongly recommend checking it out. In addition, I politely ask all readers to consider contributing to the site to keep it running. (Disclaimer: apart from being a regular user and donor, I have no other affiliation with this site.)
-
We are using bold fixed-width font for code (as is usual in
Overload
), so 98 / 10 = 9.8 is maths and
98 / 10 == 9is code. -
YMMV, reported numbers were obtained by a single run in
quick-bench.com
using GCC 8.2 with
-O3and-std=c++17[ QuickBench ]. I do not know details about the platform it runs on, especially the processor
has a PhD in Applied Mathematics from Université de Paris Dauphine. He worked as a lecturer in Mathematics before moving to the financial industry.
