








Concurrency can get confusing quickly. Lucian Radu Teodorescu presents current plans for concurrency in the VAL programming language, comparing them with other languages.
Concurrency is hard. Really, really hard. Especially in languages like C++. First, there are the safety and correctness issues: deadlocks, race condition bugs and resource starvation. Then, we have performance issues: our typical concurrent application is far from being as fast as we hoped. Lastly, concurrent code is far harder to understand than single-threaded code.
| Race conditions, deadlocks and starvation | |
|
Despite being an old problem (since 1965, older than Software Engineering), it appears that it is largely unsolved. We lack concurrent solutions that are safe, fast, and easy. This article tries to lay down the characteristics of a good concurrent model and presents a possible model that fulfils these characteristics.
The reader may be familiar with my previous work on Structured Concurrency in C++ [Teodorescu22], which argued for a good concurrency model. Here, we aim at going beyond that model, improving on the ease-of-use side.
A concurrency model
Before diving into our analysis, we have to set some definitions. These definitions may not be universally accepted; they are tailored for the purposes of this article.
Concurrency is the set of rules that allows a program to have multiple activities (tasks) start, run, and complete in overlapping time periods; in other words, it allows the activities to be executed out-of-order or in partial order. Parallelism is the ability to execute two activities simultaneously. Concurrency enables parallelism, but we can have concurrency without parallelism (e.g., a system with a single threaded hardware that implements time slicing scheduling).
Concurrency concerns only apply at program design time. One can design concurrent software that is independent of the hardware it runs on. On the other hand, parallelism is an execution concern: whether parts of a program run in parallel or not depends on the underlying hardware (both in general and at the time of execution). For this reason, we focus on concurrency, not on parallelism.
A hardware thread (core) is an execution unit that allows code to be executed in isolation from other execution units on the hardware. Multiple hardware threads enable parallelism. Software threads (or, simply, threads) are logical execution streams that allow the expression of concurrency at the OS or programming level.
Arguably, the most important concern in concurrent design is the analysis of the overlapping activities. These activities can be represented in the form of a directed acyclic graph, possibly with more constraints that cannot be expressed with graph links. For example, the constraint that two activities cannot be executed concurrently, without specifying which activity needs to be executed first, cannot be directly represented in the graph.
To handle concurrency, there are abstractions that deal with the start and the end of these activities. We call the code executed in these abstractions concurrency-control code. For example: creating a thread, spawning a thread, joining a thread, waiting for a task to complete, etc. These abstractions are usually implemented in a concurrency framework.
A concurrency model is the set of programming rules and abstractions that allows us to build concurrent applications.
For simplification, this article uses the word threads as if all threads are CPU threads. The same ideas can be extended if we think of threads of execution as being part of other execution contexts (GPU threads, compute resources in a remote location, etc.)
Safety in a concurrent world
Goal S1. The concurrency model shall not allow undefined behaviour caused by race conditions.
For most practical purposes, this means that there shouldn’t be two threads in the concurrent system that are sharing a resource in an unprotected way, in which at least one thread is writing to that resource.
Let us take a simple example. Suppose we have a shared variable in a C++ codebase of type shared_ptr<string>. One thread could be trying to read the string from the shared pointer, while another thread could replace the string object. The first thread assumes that the string object is still valid, while the second thread just invalidates the object. This will lead to undefined behaviour.
Adding mutexes around the accesses to the shared resource solves this problem, but creates other problems, as detailed below.
Goal S2. The concurrency model shall not allow deadlocks.
In concurrent systems with threads and locks, deadlocks are a common issue. This is not actually a safety issue per se; it is a correctness issue (and also a performance issue). We don’t generate undefined behaviour, but we reach a state in which at least one of the threads cannot progress any further.
***
Having these two goals, concurrent programs are as safe as programs that don’t have any concurrency.
One would want to also add lack of starvation as a goal here. While this is a noble goal, there is no concurrent system that can guarantee the lack of starvation. This is because this is highly dependent on the actual application. One cannot eliminate starvation without constraining the types of problems that can be expressed by the concurrent model. In other words, for all possible general concurrent systems, one can find an application that has starvation.
Fast concurrency
Goal F1. For applications that express enough concurrent behaviour, the concurrency model shall guarantee that the performance of the application scales with the number of hardware threads.
If there is enough independent work in the application that can be started, then adding more hardware threads should make the application execute faster. Amdahl’s law tells us that the scale-up is not linear, but, nevertheless, we should still see the performance improvements.
Let’s say, for example, that we need to process a thousand elements, and processing them can be done in parallel. If processing one element takes about 1 second, then processing all the elements on 10 cores should take about 100 seconds, and processing all the elements on 20 cores should take about 50 seconds. There are some concurrency costs when we create appropriate tasks and when we finish them, but those should be fairly insignificant for this problem.
Goal F2. The concurrency model shall not require blocking threads (keeping the threads idle for longer periods of time).
If the number of software threads is equal to the number of hardware threads, then blocking a software thread means reducing the amount of actual parallelism, thus reducing the throughput of the application.
And, because of the next goal, we generally want to have the number of software threads equal to the number of hardware threads. This implies that blocks are typically a performance problem. This means that the concurrency model should not rely on mutexes, semaphores, and similar synchronisation primitives, if they strive for efficiency.
As concurrency models usually require some synchronisation logic, this goal implies the use of lock-free schemas. Note, however, that implementations may still choose to use blocking primitives for certain operations in cases where they work faster than lock-free schemas.
Goal F3. The concurrency model shall allow limiting the oversubscription on hardware threads.
For many problems, if we have one hardware core, it’s more than twice as slow to run two threads on it than to run a single thread. Creating two software threads on the same hardware thread, will not make the hardware twice as fast; thus, we start from twice as slow. Then, we have context switching, which will slow down both activities; this is why the slowdown will be more than doubled.
Try reading two books at the same time; one phrase from one book, one phrase from another book. Your reading speed will be extremely slow.
Goal F4. The concurrency model shall not require any synchronisation code during the execution of the tasks (except in the concurrency-control code).
If one has a task in which no other tasks are created, and no tasks are expected to be completed, then adding any synchronisation code will just slow the task down. The task should contain the same code as if it were run in an environment without concurrency.
Goal F5. The concurrency model shall not require dynamic memory allocation (unless type-erasure is requested by the user).
Dynamic memory allocation can be slow. The concurrency model shall not require any dynamic memory allocation if there is no direct need for it. For example, futures require dynamic memory allocation, even if the user doesn’t need any type-erasure.
Easy concurrency
Goal E1. The concurrency model shall match the description of structured concurrency.
In the previous article ‘Structured Concurrency in C++’ [Teodorescu22], we said that an approach to concurrency is structured if the principles of structured programming [Dahl72] are applied to concurrency:
- use of abstractions as building blocks
- ability to use recursive decomposition of the program
- ability to use local reasoning
- soundness and completeness: all concurrent programs can be safely modelled in the concurrency model
If these goals are met, then writing programs in the concurrency model will be easier.
Goal E2. Concurrent code shall be expressed using the same syntax and semantics as non-concurrent code.
If there is no distinction between the concurrent code and the code that is not meant for concurrent execution, then the user will find it easier to read and reason about the concurrent code.
Of course, these principles assume that we don’t make non-concurrent code more complex than it needs to be.
Goal E3. Function colouring shall not be required for expressing concurrent code.
This can be thought of as a special case of the previous goal, but it’s worth mentioning separately, as it has a special connotation for concurrency. The term function colouring comes from Bob Nystrom’s article ‘What Color is Your Function?’ [Nystrom15]. Bob argues that different asynchrony frameworks apply different conventions to functions (different colours), and it’s hard to interoperate between such functions (colours don’t mix well).
For example, in C#, one would typically add the async keyword to a method to signal that the method is asynchronous; then, the callers would call the function with await to get the real result from such an asynchronous function. This makes the interoperability between regular methods and asynchronous methods harder, making the whole concurrency model harder for the programmer.
Goal E4. Except for concurrency-control code, the user shall not be required to add any extra code in concurrent code versus non-concurrent code.
This goal is very similar to F4, but seen from a different perspective. It is obvious that if writing concurrent programs requires us to add extra logic, then things aren’t as easy as they could be.
Ideally, the extra complexity required when writing concurrent code should be in the design of the activities that can be run concurrently, and the setting of the proper relationships between them. This is always harder than sequential code, where total ordering of activities is guaranteed.
Goal E5. The concurrency model should have a minimum set of rules for the user to follow to stay within the model.
There is no concurrency model that would not require extra thought from the programmer to write good concurrent applications. However, the fewer those thoughts are, the fewer the rules that the programmers must follow and the easier the concurrent programming would be.
A review of past concurrency modes
We will now take a few existing concurrency models and see how they match the above goals. Please see Table 1. We mark with ‘+’ the fact that a concurrency model fully meets a goal; we use ‘/’ to indicate that the goal is only partially met; lastly, we use ‘–’ to indicate that the goal is not met.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Table 1 |
For the E5 goal, we try to give a subjective measure of the concurrency rules of the model (how many there are / how complex they are), and how easy it is for an average user to master them.
Locks and threads
This is the classic model of concurrency, in which one would explicitly create threads and use locks (mutexes, semaphores and other synchronisation primitives) to synchronise between threads.
This mode is, as one would expect, one of the worst possible models. It tends to generate a lot of safety/correctness issues, and it’s hard to use correctly. Although one can create fast programs in this model, this is not guaranteed by the model itself. In fact, average concurrent code written with threads and locks is far from performant, as having numerous locks will severely slow down the application (see [Parent16, Henney17]).
Using tasks
Tasks are much better than locks and threads. If done correctly, they promise safety (although safety cannot be guaranteed by the compiler). In general, tasks can be fast, except for a dynamic memory allocation that is needed when the task is created. They don’t form a model of concurrency that meets our definition of structured concurrency [Teodorescu22]. It may not be the easiest model to work with, but it is not particularly bad either.
C# asynchronous model
For the C# world, this is not a bad model. It keeps the safety guarantees of the language, it makes some efficiency tradeoffs that are fairly common, and it has a decent ease of use. Not ideal, but in line with the general philosophy of the language.
In terms of efficiency, the model has 2 problems: it requires blocking calls and it doesn’t properly limit oversubscription. The two are closely related. Calling an asynchronous function from a regular one requires the use of a blocking call (e.g., Task.Wait or Task.WaitAll). Because threads can be blocked, the framework can associate multiple threads for a hardware core. To maintain good performance, the thread pool needs to do a balancing act, starting and stopping threads at runtime. This has a performance penalty, but it’s considered acceptable for most C# applications.
The main reason I’ve included this model in my analysis is because it’s a perfect example of function colouring. We have asynchronous functions (to be used in concurrent contexts), and synchronous ones (to be used in contexts in which concurrency is not required). Instead of having one syntax for both concurrent code and non-concurrent code, we have two syntaxes, each with slightly different rules. This hurts the ability to read the programs. But, to be honest, it is not that bad, if we consider the performance implications of synchronously waiting on tasks.
C++ coroutines
The concurrency model with C++ coroutines is very similar to the asynchronous model in C#. In C++, we just have language support for coroutines, without any library support for enabling a concurrent model. However, we can assume that people will be able to create one.
To interact between functions and coroutines, we need a blocking wait call, so the same tradeoffs apply as with the C# model. Although we can implement the same strategies in C++, the performance expectations for C++ are higher, so the model may not be considered very efficient for C++ applications.
The way coroutines are specified in the language, the compiler cannot guarantee (for most cases) the absence of dynamic memory allocation. For many problems, this is not acceptable.
In terms of ease of use, C++ coroutines behave similarly to C# asynchronous functions (ignoring the fact that in C++ everything is, by default, harder to use).
Senders/Receivers
The senders/receivers model is a C++ proposal named std::execution that is currently targeting C++26 [P2300R6]. It contains a set of low-level abstractions to represent concurrent computations efficiently, and it follows a structured approach.
This model really shines on efficiency. The proposal targets composable low-level abstractions for expressing concurrency, and there isn’t any part of the proposal that has inherent performance costs. There is no required blocking wait. For simple computations, when expressing the entire computation flow can be stored on the stack, there is no required dynamic memory allocation. However, for most practical problems we would probably have some form of dynamic tasks, and thus we need heap allocations in one way or another.
The problem with this model is its ease of use. All the computations need to be expressed using primitives provided by the proposal. Listing 1 provides an elementary example of using this framework. Ideally, the same logic should have been encoded in a form similar to Listing 2.
scheduler auto sch = thread_pool.scheduler();
sender auto begin = schedule(sch);
sender auto hi = then(begin, [] {
std::cout << "Hello world! Have an int.";
return 13;
});
sender auto add_42 = then(hi, [](int arg) {
return arg + 42; });
auto [i] = this_thread::sync_wait(add_42).value();
|
| Listing 1 |
int hello() {
std::cout << "Hello world! Have an int.";
return 13;
}
void concurrent_processing() {
thread_pool pool = ...;
pool.activate(); // move to a different thread
int i = hello() + 42;
// ...
}
|
| Listing 2 |
The code presented in Listing 2 is not that far from how one would write concurrent code with coroutines, but we removed any syntax associated with coroutines.
Rust’s fearless concurrency
Rust’s default concurrency model has an odd place in our list of concurrency models [Rust]. It promises safety, but it doesn’t deliver any guarantees to be free of deadlocks. It tries to provide access to lower-level primitives, but that typically leads to slow code. Moreover, it also fails to deliver on ease of use, as the low-level abstractions used for concurrency tend to cloud the semantics of concurrent code. The concurrent applications are cluttered with code needed for synchronisation.
The model is based on channels as a means of communicating between threads and mutexes for blocking threads to access protected shared resources. Mutexes are, by definition, blocking primitives; that is, they tend to slow down the applications. Channels allow two threads to communicate. The main problem with channels is that they often require blocking primitives; moreover, in most of the cases in which blocking primitives are not used, some kind of pooling is needed, which typically also leads to bad performance.
For some reason, whenever I hear the syntagm fearless concurrency, my mind flows to Aristotle’s ethics. Aristotle defines virtues as being the golden means between two extremes, one being excess and one being deficiency. He actually gives the example of the virtue of courage as being the right balance between being a coward and being rash (fearless). Having no fear frequently means seeking danger on purpose.
While this is just wordplay, I can’t help but think that being this fearless is not a virtue.
A possible future for concurrency
The model that I am about to describe is still in the inception phase. It is purely theoretical, there is no real implementation for it. I may be arguing for some model that cannot be built, but, for discovery purposes, I hope the reader will not mind my approach.
I am basing this model on the evolution and the ideas of the Val project [Val, Abrahams22a, Abrahams22b, Racordon22, Teodorescu23]. While this model was discussed in the Val community, and got support from the community, there is no official buy-in of the community towards this model. We see this as an experiment.
For the rest of this article, I will call this model the proposed Val concurrency model.
The concurrency model has three pillars:
- Val’s commitment to safety would imply safe concurrency.
- The model aims at being as efficient as senders/receivers, but uses coroutine-like syntax.
- Reduce function colouring to make concurrent code look similar to non-concurrent code.
An example
Listing 3 shows an example of a concurrent program in Val. We have three innocent-looking functions. The long_task and greeting_task functions are regular functions; they produce integer values on the same thread they were started on. If the greeting_task function is called on the main thread, the long_task function is called on a worker thread (as it is started with spawn). The concurrency_example function is different: it starts executing on one thread (the main thread) and most probably it finishes executing on a worker thread. From the user’s perspective, all three are still functions, but there is a slight generalisation regarding threading guarantees.
fun long_task(input: Int) -> Int {
var result = input
for let i in 0 ..< 42 {
sleep(1)
&result += 1
}
return result
}
fun greeting_task() -> Int {
print("Hello world! Have an int.")
return 13
}
fun concurrency_example() -> Int {
var handle = spawn long_task(input: 0)
let x = greeting_task()
let y = handle.await() // switching threads
return x + y
}
fun main() {
print(concurrency_example())
}
|
| Listing 3 |
Figure 1 shows a graphical representation of the tasks involved in this program.
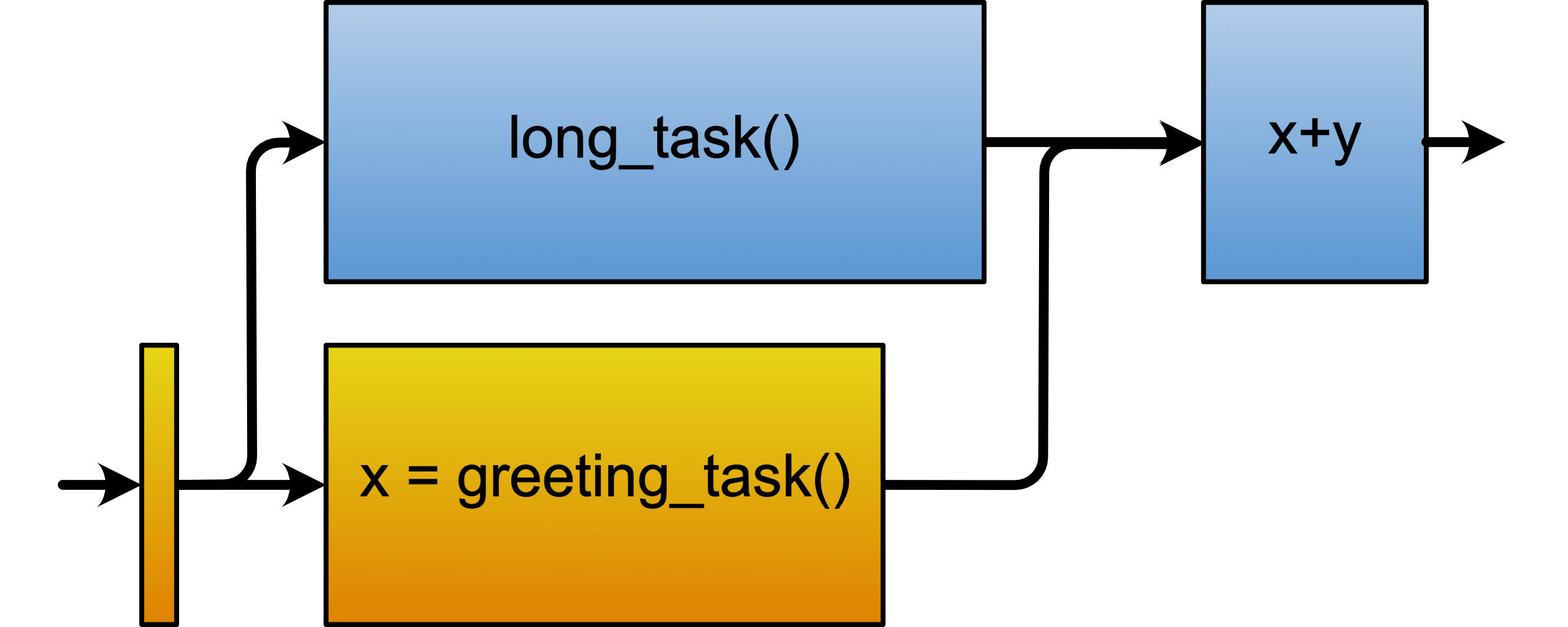 |
| Figure 1 |
Computations, senders, coroutines, and functions
In the ‘Structured Concurrency in C++’ article [Teodorescu22], we defined a computation as a chunk of work that can be executed on one or multiple threads, with one entry point and one exit point. We argued that the exit point doesn’t necessarily have to be on the same thread as the entry point. This article tries to show that, if we consider computations to be the basis of computing, we can build any concurrent program on top of them.
In C++, the senders/receivers proposal can be built upon the computation model to provide structured concurrency. Every computation can be modelled with a sender. This provides an efficient basis for implementing computations.
Moreover, we can use C++ coroutines to represent computations. In fact, the senders/receivers model [P2300R6] provides a (partial) equivalence relation between senders and coroutines. Coroutines can be easier to use than senders, and thus it makes sense to consider them when designing a user-friendly concurrency model.
In the proposed Val concurrency model, all functions are coroutines, even if the user doesn’t explicitly mark them. This means that Val functions can directly represent computations, and thus can be used for building concurrent programs.
With this in mind, the code from Listing 3 can be translated to C++ as something similar to the code from Listing 4. The long_task function is automatically put through a coroutine, and waiting for its result looks like calling co_await on the coroutine handle. This indicates that the proposed Val concurrency model can be easy to use.
int long_task(int input) {
int result = input;
for (int i=0; i<42; i++) {
sleep(1);
result += 1;
}
return result;
}
task<int> long_task_wrapper(int input) {
co_await global_task_pool.enter_thread();
co_return long_task(input);
}
int greeting_task() {
std:: cout << “Hello world! Have an int.”;
return 13;
}
task<int> concurrency_example() {
auto handle = long_task_wrapper(0);
auto x = greeting_task()
auto y = co_await handle;
co_return x + y;
}
|
| Listing 4 |
Concurrency operations
If concurrency is defined as being the execution of activities in partial order, one of the main activities in concurrency design should be establishing the relationships between activities. That is, the rules that govern when activities can be properly started, or what needs to happen when an activity is completed. If we see the execution of the program as a directed acyclic graph, the main focus of concurrency should be on the links of the graph.
As argued above, a good concurrency model shall not require any synchronisation code except the start/end of the activities (what we called concurrency-control code).
In our proposed model, starting new activities is signalled by the spawn construct. By default, new work goes on a default thread pool. The user can change this behaviour and provide a scheduler (term borrowed from [P2300R6]), so the new activity will start in the specified execution context.
Calling spawn f() in Val would be equivalent to a C++ sender schedule(global_scheduler) | then(f) and starting that sender. The result of such an operation would be represented by something like Async<T>. This result can then be awaited to get the actual value produced by the computation.
It is important to note that awaiting on such an asynchronous result may switch the current thread. This is considered an acceptable behaviour in our model.
It turns out that spawning new work, and awaiting the result of that work, are the only two activities needed to express concurrency. This is consistent with the other async/await models [Wikipedia].
C++ coroutines are not scalable
If we want programmers to avoid synchronous waits, then coroutines are pervasive. If a coroutine switches threads, then the caller coroutines also switch threads. Unless at the end of the caller we do a synchronous wait for the initial thread, the caller also needs to be a coroutine. The same reasoning then applies to its caller, and so on until we reach the bottom of the stack.
Thus, avoiding synchronous waits implies that we have to transform a large part of our functions into coroutines. This is obviously bad.
First, the function colouring problem affects most of the code. The language stops being concurrency-friendly.
Then, we have performance implications. For every coroutine we create, there is a potential heap allocation. If most of our functions need to be coroutines, this cost is much too high.
Another approach for coroutines
C++ coroutines are stackless. They don’t require the entire stack to be available, and all the local variables of the coroutine will be placed on the heap (most probably). This limits the ability of the coroutine to suspend; it can only suspend at the same level as its creation point; it cannot suspend inside a called function.
Another way to model coroutines is to use stackful coroutines [Moura09]. Boost libraries provide support for such coroutines [BoostCoroutine2]. For these types of coroutines, we keep the entire stack around. We can suspend such a coroutine at any point. This alone is a big win in terms of usability.
Coming back to our initial problem with coroutines, calling stackful coroutines doesn’t require special syntax or special performance penalties.
The stackful coroutines have performance downsides too. They require memory for the full stack. If, for example, a function with a deep stack creates many coroutines, we need memory to fit multiple copies of the original stack. There are ways to keep the costs under control, but there are nevertheless costs.
Using stackful coroutines for our concurrency implementation, the good news is that we would only pay such costs when we spawn new work, when we complete concurrent work, and whenever we want to switch threads. The performance costs would be directly related to the use of concurrency, which is what most users would expect.
More performance considerations
This model is consistent with other async/await models [Wikipedia]. Thus, it doesn’t need any synchronisation primitives during the execution of tasks. This means that Goal F4 is met by design. Furthermore, using functional composition for asynchronous operations, our proposed model meets Goal F1, which requires that performance scales with the number of performance threads (if the application exhibits enough concurrent behaviour).
Moreover, because calling await doesn’t imply blocking the current thread, Goal F2 is also met. The proposed model allows limiting oversubscription by using an implicit thread pool scheduler for the spawn calls; this means Goal F3 is also met .
Finally, there is Goal F5, which requires the model not to perform heap allocation for creation of work and getting the results out of the work. This is trickier.
As we just discussed, the stackful coroutines model may require heap allocations when a new coroutine is created. While implementations can perform tricks to amortise the cost of allocations, in essence we still require memory allocation.
Thus, our proposed model only partially meets Goal F5. All the other goals are met.
We believe that the compromise put forward by the model will turn out to be efficient for the majority of practical problems. But, time remains to tell whether we are correct.
Easiness and safety
As the reader may expect, the proposed Val concurrency model meets all the goals for ease of use. In essence, the functions of the language are also the primitives to be used for concurrency. The simplest model possible.
The set of rules that the programmer needs to know for concurrent programming is almost identical to the rules for non-concurrent programming. The difference is the semantics of spawn (including the use of schedulers) and the semantics of the await functions.
One thing that needs highlighting is local reasoning. Unlike most imperative languages, with Val’s Mutable Value Semantics, a variable cannot be used in a code block that is mutated outside that code block. This takes local reasoning to its maximum: to reason about a code block, one doesn’t need to consider other, non-related code. This is true for single-threaded code as well as for concurrent code.
In terms of safety, the model builds upon the safety guarantees of Val. This means that there cannot be any race conditions. Furthermore, because we are not using locks, there cannot be deadlocks. As both of these conditions are met, concurrent programming gets to be free of headaches, or, at least, as free as single-threaded programming.
Analysis of the proposed model
In the previous section, we focused on describing the proposed concurrency model and showing how well it meets our goals. In this section, we look at some other implications for the model.
Threads are not persistent
Imagine the code from Listing 5. Because of the spawn / await constructs from f2, the thread is most likely switched inside f2 . If f2 switches threads, then f3 also needs to switch threads. All the functions on the stack can possibly switch threads.
fun f1() {}
fun f2() {
var handle = spawn f1()
handle.await() // switching threads
}
fun f3() {
f2() // switching threads
}
|
| Listing 5 |
In this model, threads are not persistent for the duration of a function. Functions can be started on one thread, and they on another thread. This might be surprising for some users, but we believe that most people will not be affected by this.
This fact can also give us some advantages. One can use sequential code that switches execution contexts, like the code from Listing 6. In this snippet, one can move between execution contexts when processing data, clearly expressing the transformation stages for processing requests, and their execution contexts.
fun process_request(c: Connection) {
io_thread.activate() // ensure we are on
// I/O thead
let incoming_request = c.read_and_parse()
cpu_thread_pool.activate() // move to the
// CPU thread
let response = handle_request(incoming_request)
io_thread.activate() // go back to the
// I/O thread
c.write_response(response)
}
|
| Listing 6 |
No thread-local storage
If threads are not persistent, one cannot properly talk about thread-local storage. With every function call, the current thread can change, so thread-local storage becomes an obsolete concept.
Removing the ability to use thread-local storage is also needed for a different reason: it breaks the law of exclusivity [McCall17]. Thus, this construct should be present in languages like Val.
Interoperability
The use of stackful coroutines would make the language harder to interoperate with other languages. If other languages call Val functions, the functions need to be wrapped/adapted to ensure that the assumptions of the other languages are met. That is, the wrapped functions must guarantee that the threads won’t change while executing these functions.
The problem with such adaptation of function calls is that it most likely introduces performance penalties.
Conclusions
We started this article as a search for a better concurrency model. One that allows us to write safe programs, that are fast and easy to reason about. We defined the goals for an ideal concurrency model, and we looked at past concurrency models to see how they meet our goals. Not surprisingly, most models have drawbacks, in at least one area.
In the other half of the article, we tried to sketch a new concurrency model that would (almost fully) meet all our criteria. This model is based on the goals of the Val programming language, and it aims at fully delivering a safe and easy experience, being as fast as possible.
Val is an experimental language. This concurrency model is an experiment within the Val experiment. This word play seems appropriate, as one of the goals for being structured is to be able to recursively decompose problems.
Regardless of the success or failure of the experiment, the goal appears to be worthwhile: searching for a better concurrency model. And, if everything goes well, and our experiment succeeds, the search will end with the implementation of this model. Time will tell.
References
[Abrahams22a] Dave Abrahams, ‘A Future of Value Semantics and Generic Programming (part 1)’, C++ Now 2022,
https://www.youtube.com/watch?v=4Ri8bly-dJs
[Abrahams22b] Dave Abrahams, Dimitri Racordon, ‘A Future of Value Semantics and Generic Programming (part 2)’, C++ Now 2022, https://www.youtube.com/watch?v=GsxYnEAZoNI&list=WL
[Aristotle] Aristotle, Nicomachean Ethics, translated by W. D. Ross, http://classics.mit.edu/Aristotle/nicomachaen.mb.txt
[BoostCoroutine2] Oliver Kowalke, Boost: Coroutine2 library, https://www.boost.org/doc/libs/1_81_0/libs/coroutine2/doc/html/index.html
[Dahl72] O.-J. Dahl, E. W. Dijkstra, C. A. R. Hoare, Structured Programming, Academic Press Ltd., 1972
[Henney17] Kevlin Henney, ‘Thinking Outside the Synchronisation Quadrant’, ACCU 2017 conference, 2017, https://www.youtube.com/watch?v=UJrmee7o68A
[McCall17] John McCall, ‘Swift ownership manifesto’, 2017. https://github.com/apple/swift/blob/main/docs/OwnershipManifesto.md
[Moura09] Ana Lúcia de Moura, Roberto Ierusalimschy. ‘Revisiting coroutines’ ACM Transactions on Programming Languages and Systems (TOPLAS), 2009.
[Nystrom15] Bob Nystrom, ‘What Color is Your Function?’, http://journal.stuffwithstuff.com/2015/02/01/what-color-is-your-function/
[P2300R6] Michał Dominiak, Georgy Evtushenko, Lewis Baker, Lucian Radu Teodorescu, Lee Howes, Kirk Shoop, Michael Garland, Eric Niebler, Bryce Adelstein Lelbach, std::execution, 2023, http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/p2300r4.html
[Parent16] Sean Parent, ‘Better Code: Concurrency’, code::dive 2016 conference, 2016, https://www.youtube.com/watch?v=QIHy8pXbneI
[Racordon22] Dimitri Racordon, ‘Val Wants To Be Your Friend: The design of a safe, fast, and simple programming language’, CppCon 2022, https://www.youtube.com/watch?v=ELeZAKCN4tY&list=WL
[Rust] Steve Klabnik, Carol Nichols, community ‘Fearless Concurrency’, https://doc.rust-lang.org/book/ch16-00-concurrency.html
[Teodorescu22] Lucian Radu Teodorescu, ‘Structured Concurrency in C++’, Overload 168, April 2022, https://accu.org/journals/overload/30/168/teodorescu/
[Teodorescu23] Lucian Radu Teodorescu, ‘Value-Oriented Programming’, Overload 173, February 2023, https://accu.org/journals/overload/31/173/teodorescu/
[Val] The Val Programming Language, https://www.val-lang.dev/
[Wikipedia] Async/await: https://en.wikipedia.org/wiki/Async/await
has a PhD in programming languages and is a Staff Engineer at Garmin. He likes challenges; and understanding the essence of things (if there is one) constitutes the biggest challenge of all.
