








How do you untie the knotty problem of complexity? Lucian Radu Teodorescu shows us how to divide and conquer difficult problems.
“The life which is unexamined is not worth living” says Socrates, according to Plato [Apology]. This should apply both to personal life, but also to professional life. Thus, it needs to be our duty to analyse various aspects of Software Engineering. And, what is more important to analyse than the fundamentals of our discipline?
This article aims to analyse one of the most useful techniques in software engineering: the divide et impera (Divide and Conquer) technique. And maybe the most useful one.
We define the divide et impera method as a way of breaking up a problem into smaller parts and fixing those smaller parts. This applies to recursive functions (where the phrase divide et impera is most often used), but it will also apply to the decomposition of problems. At some point, we will also discuss using abstraction as a way of applying divide et impera. Finally, we will show how to use this technique in our daily engineering activities that are not strictly related to coding.
Definition, generalisations, and distinctions
In this article, we call divide et impera a method of approaching problems that has the following characteristics:
- breaking the problem into sub-problems
- solving the sub-problems independently of each other
- occasionally, an answer to a sub-problem may render solving the rest of the sub-problems unnecessary
- sporadically, a small amount of information passes one sub-problem to another
- combining the results of the sub-problem solutions to form the solution to the initial problem
We take a relaxed view on what a problem can be. In our exposition, it may mean a software algorithm, as expressed in code (e.g., quick-sort algorithm), or maybe the actions that a software engineer needs to do to complete a task (e.g., fixing a defect may imply analysis of the defect, discussions with other engineers, and perhaps closing the defect as ‘by design’).
Please note that this definition is more general than what’s typically understood by the Divide and conquer algorithm [Wikipedia-1], which requires the sub-problems to be of the same nature, similar to the original problem, but simpler. In our case, we allow the sub-problems to be widely different from each other (and different from the original problem, too).
Our definition overlaps in a greater measure with the decomposition technique [Wikipedia-2]. Decomposition techniques tend to be associated with breaking down software systems. In our definition, we incorporate that, but we will also apply the same technique to processes outside the code (debugging, programming methodologies, etc.).
Truth be told, the name decomposition fits better than divide et impera; I’m choosing the latter name because, besides decomposition (i.e., divide), it also highlights the idea of conquering (i.e., impera) the sub-problem. The main point of applying this method is to simplify the original problem, and we are doing this by making the sub-problems much more approachable, easy to conquer.
Simplifying complexity
The typical model for analysing the complexity of a system is to look at the interaction within its parts. If the system has n parts, then it may have up to n(n-1)/2 interactions between these parts. We may associate complexity with each of the parts, and with each interaction between these parts. If the complexity associated with a part is c0 and the complexity associated with an interaction is ci, then the total complexity of the system is:
C = c0 ∙ n + ci ∙ n ∙ (n-1) / 2
Its magnitude would be O(C) = n2.
One can easily remark here that the bulk of the complexity arises from the interaction between parts, not from the parts themselves. Thus, limiting the interaction between parts would be beneficial.
Let’s take an example. Let’s consider a system of n = 10 parts, and complexity values c0 = ci = 1. The total complexity of the system, if we had interactions between all parts, would be C = 10 + 45 = 55. Now, let’s assume we could group the parts into two groups, such that the parts from one group and the parts from the other don’t interact with each other, just one interaction between the groups. If we do that, the complexity of each group would be Cp = 15, and the total complexity of our system C' = 15 + 15 + 1 = 31. Thus, this grouping does a reduction in terms of complexity of 1.77 times.
In our method, we divide a problem into sub-problems not to create more parts that interact with the rest of the parts, but to isolate the interactions; this is why we require the problems to be able to be solved independently of each other.
The two main benefits of this method are that it:
- simplifies reasoning about the problem
- makes the solving of the problem easier (performance improvements)
Let’s start by analysing the second benefit, and let’s use examples to drive that analysis.
Algorithmic examples
Merge sort
The idea of the merge-sort algorithm is relatively simple:
- divide the initial range of values into two halves;
- sort the two halves independently;
- the sorting of the halves can be done recursively;
- finally, combine the two sorted sub-ranges into the resulting sorted range.
This would be implemented similar to the code in Listing 1.
template <typename BidirIt>
void mergeSort(BidirIt begin, BidirIt end) {
if (begin < end) {
// break down the problem
BidirIt mid = begin + (end-begin)/2;
// solve sub-problems independently
mergeSort(begin, mid);
mergeSort(mid, end);
// combine the results
std::inplace_merge(begin, mid, mid, end);
}
}
|
| Listing 1 |
The complexity of the algorithm is O(n log n) (assuming we always have enough memory to perform the merging). The breaking down of the problem into sub-problems is trivial: just compute the middle of the input range; this will divide the initial range into two sub-ranges. The two sub-ranges can be sorted independently of each other: to sort the left sub-range, we don’t need any information from the right sub-range. Each sort will be done in O(n log n).
Merging is slightly more complex, but this is doable in O(n) (if enough memory is available). If we ignore the fact that the merging algorithm can work in-place, the fundamental idea can be expressed as:
- while both input arrays have remaining values:
- compare current elements of both input arrays;
- copy the smaller element into the output array;
- advance the current pointer for the array containing the smallest element;
- copy to the output array the remaining elements.
It is important for us to analyse the possible interactions between the elements of the arrays being merged. Because the arrays are sorted, an element is related to its adjacent elements in the same array, but it doesn’t need to be compared/considered with any other elements. When merging, we compare elements from one array to elements from the other array. Again, here we only look at a limited set of interactions; when placing the left-side element lcur into the output array, we only look at the elements from the right-side that have values within the range lprev, lcur), where lprev is the previous element in the left-side array. For the entire merge process, we have O(n) in interactions, if the output array contains n elements.
We need to contrast these complexities with a naive approach (e.g., insertion sort) to sorting, in which we compare each element with all the other elements, which has a complexity of O(n2). We can see how the merge sort algorithm has lower complexity than a naive sorting algorithm.
Quicksort
Another good example for showcasing the divide et impera method is the quicksort algorithm. See Listing 2 for a possible implementation of the core algorithm. It has the same complexity of O(n log n) as merge sort, but it achieves it differently. Instead of combining the sorted sub-ranges, in quicksort we ensure that all elements on the left side are smaller than the elements on the right side. Doing this, assures us that there is nothing we need to do after we’ve sorted the sub-ranges.
template <typename BidirIt>
void quickSort(BidirIt begin, BidirIt end) {
if (begin < end) {
// break down the problem
BidirIt mid = pivot(begin, end);
partitionElements(begin, mid, end);
// solve sub-problems independently
quickSort(begin, mid);
quickSort(mid, end);
// nothing to combine
}
}
|
| Listing 2 |
For this algorithm, the choice of the middle element (called pivot) is important, as it may change the complexity of the algorithm to be O(n2). For this article, we assume we are using a scheme that guarantees the O(n log n) complexity.
Binary search
We need to analyse another example to highlight an important point of our divide et impera method: binary search; for a given sorted sequence of values, check if a given value is in the sequence. Please see Listing 3 for a possible implementation.
template <typename BidirIt, typename T>
bool binarySearch(BidirIt begin, BidirIt end,
const T& value) {
if (begin < end) {
// break down the problem
BidirIt mid = begin + (end-begin)/2;
// solve the sub-problems independently,
// with short-circuit
if (value == *mid)
return true;
else if (value < *mid)
return binarySearch(begin, mid, value);
else
return binarySearch(mid, end, value);
// nothing to combine
}
else
return false;
}
|
| Listing 3 |
Here, we are doing minimal work to break down the problem, similar to merge sort. We are doing nothing to combine the results of the sub-problems, similar to quicksort. What is remarkable in this example is that we are short-circuiting the solving of the sub-problems. If we determine that the solution must be in the first half of the sequence, it doesn’t make sense for us to do anything for the second half.
The complexity of the binary search algorithm is O(log n), better than the complexity of O(n) of doing a linear search.
***
We have briefly covered, with examples, the important part of the divide et impera method, the way we defined it: there is a part in which we split the problem, there is a part in which we solve the sub-problems, and there is an optional part in which we combine the results. We’ve also looked at a trivial example in which doing work for sub-problems may be short-circuited.
It is important to mention that the splitting and the combining parts also have costs associated with them. However, it seems that a proper division of the problem into sub-problems would compensate for these costs.
We looked at how divide et impera can help improve the efficiency of software algorithms. We will look at applying the method to reasoning about software.
Reasoning with divide et impera
In the landmark Structured Programming book [Dahl72], Dijkstra argues that one of the major sources of difficulties in software engineering is our human inability to capture large programs in our head.
Reasoning about programs, where one needs to keep track of all parts of the software, quickly grows to be impossible with the increase in the size of the program. Like we mentioned above, for a program with n parts (e.g., instructions) the complexity that one needs to maintain in their mind is O(n2). And, studies show that, on average, our mind can keep track of 7 independent things at one time [Miller56].
To alleviate this problem, Dijkstra advocated that we must add structure into our programs, such as the interaction between different parts of the software is reduced. He argues that there are three main mental aids that allow us to better understand a problem: enumeration, mathematical induction, and abstraction. To some extent, they all overlap with divide et impera.
The idea behind enumerative reasoning is that it is (somehow) easy for humans to reason linearly on a sequence of instructions, especially if the sequence of instructions aligns with the execution of the program. Looking at the first instruction, one doesn’t need to care about the rest of them. Looking at the second instruction, it may require understanding of the results of the first one, but doesn’t require any understanding of the following instructions. And so on.
Dijkstra also considers blocks of code with one entry point and one exit point as a complex instruction. Thus, if, switch and while blocks can also be instructions. Furthermore, more importantly, we can make use of abstraction (i.e., making function calls) just like primitive instructions.
To the extent that the instructions are independent of each other, we apply divide et impera. While we have said that our method allows information to flow from one sub-problem to another, the amount of information passed around needs to be small for the payoffs of the methods to show.
Listing 4 shows a possible implementation of std::remove, trying to showcase the sequencing as a way to reduce cognitive load. In the first step in the algorithm, we find the first occurrence of the given value. The second step of the algorithm, if there is a match, is to shift left all subsequent elements by one position. One can reason about the first sub-problem completely independently from reasoning about the second sub-problem.
template <typename ForwardIt, typename T>
ForwardIt remove(ForwardIt first,
ForwardIt last, const T& value) {
// subproblem 1: find the (first) occurence of
// our value
first = std::find(first, last, value)
// subproblem 2: shift left one position
// subsequent elements
if (first != last) {
for (auto it = first; ++it != last; ) {
if (!(*it == value)) {
*first++ = std::move(*it);
}
}
}
return first;
}
|
| Listing 4 |
The mathematical induction mental aid that Dijkstra mentions is helping us cope with loops. While one can find similarities between this reasoning and divide et impera, the two are somehow distant, so we won’t cover their connection here.
The last mental aid that Dijkstra identified, perhaps the most important one, is abstraction. Abstraction stays at the core of what Dijkstra considers to be structured programming. The main idea is that abstraction allows the programmer to lose sight of (abstract out) unimportant details, while focusing only on important parts.
For example, for the std::remove function that we just discussed, the implementation details are irrelevant for someone that just wants to use the function according to the promised contract. There are many ways this function can be implemented, but it doesn’t matter that much if they all satisfy the same contract. Thus, our cognitive load for using this function is lowered.
The reader is probably starting to realise where I’m going with this: the simple use of an abstraction is an application of divide et impera, as it separates the bigger problem into two sub-problems: implementing the abstraction and using the abstraction. We are applying the method not necessarily to the code itself, but to our reasoning about the code.
In our definition of the method, we identified a prerequisite step that is breaking down the problem into sub-problems. This is the definition of the function contract: the type of the function (parameters and return type), constraints around the function, complexity guarantees, etc.
It’s not directly obvious whether there is a step that ‘combines the results of the sub-problems’ in the case of using function abstractions. One may argue that the simple realisation that calling the function will actually execute the body of the function is such a step. Yes, this is so fundamental that we don’t consciously think about this every time we use a function, but that doesn’t mean that this thought process isn’t followed at some point. I do feel that we should consider this realisation as part of the process.
Thinking about the use of abstractions in terms of divide et impera allows us to realise the benefits of using the abstractions. To take an example, let’s assume that we write a function once, and we use it n times; assuming the function doesn’t have bugs, and the contract of the function is well understood, we only have to reason about the implementation of that function once. Thus, the total cost of using the function would be Ctotal = Cimpl + n ∙ Ccontract, where Cimpl is the mental cost spent while implementing the function and Ccontract is the cost of understanding the function contract in order to use it. If n > 1 and Ccontract < Cimpl ∙ (n-1)/n, which is probably true for most of the functions, then we are reducing the cognitive load to use this abstraction.
The reader should note that this applies to all types of abstractions, not just functions. We can have similar arguments for classes, concepts, etc.
Dijkstra uses the mental aids to build a model of how programs should be structured, describing a process for constructing programs. This process is essentially decomposition. In one of the lengthier examples he gives, printing a table of the first thousand prime numbers, he starts from the top, and recursively divides the problem at hand into multiple subproblems and solving those problems. The key point here is that, when a problem is divided into sub-problems, the sub-problems can be worked on in isolation. This is precisely what we discussed under the term divide et impera.
What is interesting to notice in Dijkstra’s exposition is that we can easily decompose programs without necessarily needing abstractions. He starts by representing the problem with placeholders (English sentences), and through repeated refinements he gradually transforms all the placeholders into actual code.
I would recommend everyone to go through the decomposition exercise that Dijkstra presented [Dahl72]. It’s a prime example of how to build a program, and how to reason about it.
Practical tips
Techniques for writing sustainable code
Good software needs to be sustainable software. Software that starts to rot from its inception, software that is hard to fit in your brain, is the opposite of what we want. But how do we write sustainable software?
The book Code that Fits in Your Head by Mark Seemann [Seemann21] tries to answer this question by providing numerous tips on writing sustainable code. Not surprisingly, many of these tips are related to our divide et impera method.
In one of the most important tips in the book, Mark offers a direct invitation to divide large problems into smaller ones:
No more than seven things should be going on in a single piece of code.
There are many techniques that Mark explains in his book; it would be too long to analyse them here, but at least we can mention some of them:
- Fractal architecture
- The 80/24 rule (write code that fits into an 80/24 screen terminal)
- ‘Arrange, act, assert’ pattern for writing tests
- Command Query Separation
- Red Green Refactor (used in TDD)
- Slicing (work in small increments)
- Strangler
- Etc.
Incremental development
Some techniques mentioned above may seem a bit farther away from our definition of divide et impera. They would fit more into the incremental development paradigm. What would be the connection between incremental development and divide et impera?
We shall argue that incremental development is a form of divide et impera. Let us analyse.
Let’s say we have a complex project P and we approach it incrementally, and we will end up solving this problem by performing the increments I1, I2, ..., In. Assuming that the project was successfully completed, we have P = I1, I2, ..., In. A naive application of divide et impera would suggest that we should break down P into P1 and P2, where P1 = I1, I2, ..., I⸤n/2⸥ and P2 = I⸤n/2⸥ + 1 ..., In (assuming the increments are roughly the same size).
The problem is that, in practice, we don’t properly know the increments upfront. To perform this division, we need to precisely know their number. And, for most software engineering problems, we simply don’t.
If we intuitively try to divide the big problem into two halves, and jump ahead to solving the first half, we probably end up with a mess. The first half is also very complex, so it accumulates delays, technical debt and poor quality. I’ve seen many projects go down this route. (That does not imply that we shouldn’t be combining this type of division with incremental development; I can argue that this combination would be the best approach.)
Using incremental development, we perform a division that is very uneven. We divide P into two parts: I1 and everything else. We need to have clean boundaries for what I1 means so that we know that we solve it correctly. After solving I1 we apply the same process and divide the rest into I2 and what comes after. We apply this repeatedly until we finish all the iterations and solve the initial problem.
This is equivalent to an unbalanced binary tree, as shown in Figure 1.
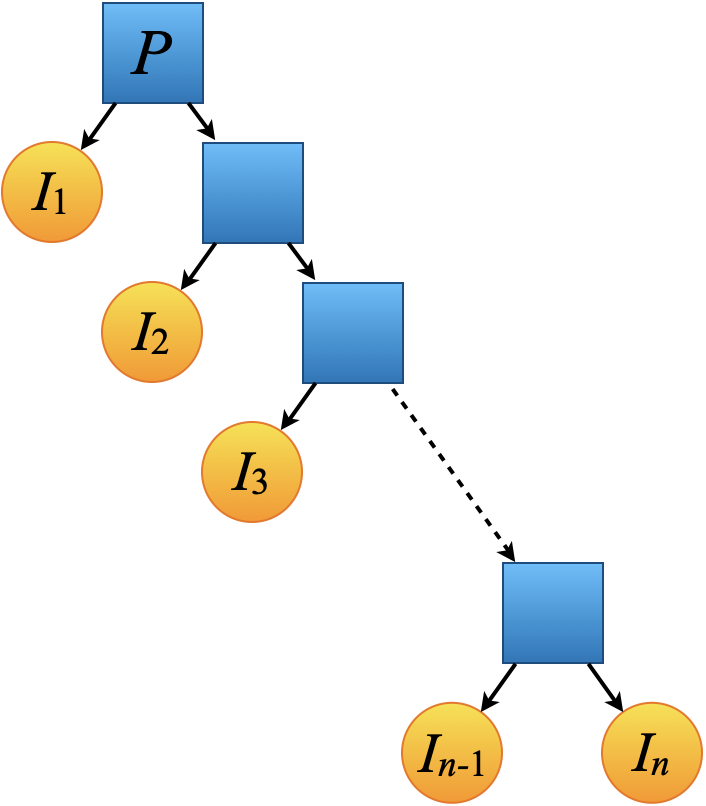 |
| Figure 1 |
Let’s look at the elements on our definition of divide et impera and see how they fit incremental development. Breaking down the problem into sub-problems consists of identifying the first increment that can be done. It is important at this step to have a clear definition of ‘done’, and ensure that we don’t redo the effort for I1 in the next sub-problem; that is, the two sub-problems must be independent. The sub-problems are the first increment and the rest of the problem. The combining step is typically non-existent.
Bisection
Git bisect is a great example of divide et impera. If we have a bug that appeared between two different releases, and there are multiple commits in between, we can use this method to narrow down the search. It is essentially an implementation of the binary search algorithm discussed above.
The important aspect of this method is finding a good way to expose the bug (i.e., have a definite test). This test needs to be accurate. If the test indicates that the bug is present, it means that it was introduced in a prior commit; if the test indicates that the bug is not present, it might have been introduced in a later commit.
Debugging tips
Let’s say we have a bug in a large code that is hard to understand, and we need to find the source of this bug.
One method of approaching this problem is looking at different pieces of the codebase and trying to understand/debug whether the bug comes from there. This technique can be useful for experts as they probably have good intuition of what could be the possible causes for the bug. But, in general, this can be an expensive method of searching for the bug. Especially if we don’t have a good test for the bug, the exploration space needed to detect the bug is massive (considering that we often look at the same part of the code multiple times). The method is related to the bogosort algorithm that tries different permutations until it finds one that is good.
Another method of analysing is to linearly look at the entire flow. That is typically expensive for complicated flows with many steps. We need to clearly understand all the expected outputs for all the steps, typically for every instruction in the codebase.
A better approach is to apply divide et impera (if possible). The idea is to find a point, ideally around the middle of the flow, where we can relatively easily check to see whether we are behaving correctly or not. This divides the search space in two parts: what happens before that point, and what happens after. In other words, it’s a manual bisection.
The test points are best to be chosen to be easily testable. For example, at the end of a quick-sort, it’s easy to see whether the sorting contract is met or not; on the other hand, if one adds a breakpoint somewhere in the partition function, sometime during the execution of the algorithm, it may be harder to understand whether the algorithm is working as expected.
If we have a client-server application, then checking the messages sent between the two would be a good start. If the requests don’t follow the agreed protocol, it’s probably a client problem. On the other hand, if the responses don’t follow the agreed protocol, it’s most likely a server issue.
For complex flows, I often used a form of printf debugging to divide the search space and narrow down on the problem. I carefully choose the test points and dump the information available at those points, and then I can reason whether the outputs are expected or not.
To be honest, I rarely use a proper debugger. It tends to create a linear flow, and it doesn’t necessarily show the actual values that are important for the entire flow. In the end, I find using a debugger slows me down when investigating issues.
Solving complex problems: first breakdown
If we have a complex problem, attacking it directly tends to lead to failure, or at least consumes a large amount of energy/time. One of the chief difficulties of a complex problem is actually understanding the problem in its entirely and its boundaries. If we clearly understand the problem, it’s much easier to provide a solution.
Thus, solving a complex problem should have 2 steps:
- Understand the problem and its limits
- Actually solve the problem
I often say that understanding the problem is the harder part of the two.
This may sound commonsense, but unfortunately, I’ve seen too many cases in which we start implementing a solution before clearly understanding the problem we are trying to solve.
Solving complex problems: prototypes and mathematical models
After the problem is clearly defined, we can actually start solving it. If the problem is complex, there may be multiple possible alternatives to solving it. Choosing the right alternative to use is hard. If we select a bad alternative, we either don’t solve the problem (e.g., the solution doesn’t have all the desired quality attributes), or we solve it with large costs. Thus, it makes sense to spend some more time at the beginning to figure out the shape of the solution.
We can spend this investigation time doing prototypes or mathematical models for the problem. Oftentimes, just performing some back-of-the-envelope calculations proves extremely valuable; they can determine whether a particular solution fits the problem or not. If the initial effort is small compared to the overall costs of implementing a solution, then that effort is well spent.
What we are arguing is that we divide the implementation part into two sub-problems: figure out the right approach and actually implement the solution
To be honest, this idea prompted me to write this article. At the beginning of the day on which I started to write this article, I had another topic in mind to write about. But then, during the day, I had a discussion with a fellow engineer who wanted to implement a better version of a task scheduler. He tried to explain to me the model that he wanted to implement and expressed the desire to start coding soon; I started to suggest that he should first build a mathematical model of the solution, to analyse what would be the consequences of implementing that algorithm; more specifically, we wanted to understand if the new algorithm can be better than the existing algorithm. Going meta, like I often do, I started to argue that we should use divide et impera to attack these types of programs. And this was the seed for the article.
Coming back to complex problems, if there are multiple solutions that may or may not work, we should spend time upfront screening for possible solutions. If we put this together with what we argued in the previous section, solving complex problems often requires solving three different sub-problems:
- properly defining the problem
- do a screening of potential solutions, and choose the right solution
- implement the chosen solution
Conclusion
We argued, in this article, that one of the most useful methods in software engineering is divide et impera. As there are multiple possible meanings for this, we tried at the beginning of the article to formulate a definition of the method that would be general enough to fit other definitions. We positioned divide et impera as a general method that can be applied both to organising code, and to how we are working.
We argued that this method is one of the widely used methods for solving problems in our field. It overlaps with the recursive method used in algorithms, it overlaps with decomposition, it’s a method that stands behind several core ideas of structured programming, and it also stands behind several practices in software engineering.
During the course of the article, we provided a series of examples of how this method can be used. The examples cover things like algorithms, reasoning about code as long as examples on applying divide et impera in day-to-day work, from development methods to more concrete tips.
I’m always of the opinion that we should be constantly analysing important things around us. That is why a method like divide et impera is worth analysing, and that’s precisely what this article sets out to do. At the end, if I should name two tips for software engineers, those would be: constantly analyse and apply divide et impera. In other words, Enodo, divide et impera.1
References
[Apology] Plato, Apology, translated by Benjamin Jowett, http://classics.mit.edu/Plato/apology.html
[Cormen22] T. H. Cormen, C. E. Leiserson, R. L. Rivest, C. Stein, Introduction to algorithms (third edition), MIT press, 2022
[Dahl72] O.-J. Dahl, E. W. Dijkstra, C. A. R. Hoare, Structured Programming, Academic Press Ltd., 1972
[Miller56] George A. Miller, ‘The magical number seven, plus or minus two: Some limits on our capacity for processing information’, Psychological Review. 63 (2), 1956, available at: http://psychclassics.yorku.ca/Miller/
[Seemann21] Mark Seemann, Code That Fits in Your Head : Heuristics for Software Engineering, Pearson, 2021
[Wikipedia-1] ‘Divide-and-conquer algorithm’, published on Wikipedia, https://en.wikipedia.org/wiki/Divide-and-conquer_algorithm
[Wilkipedia-2] ‘Decomposition (computer science)’, published on Wikipedia, https://en.wikipedia.org/wiki/Decomposition_(computer_science)
Footnote
has a PhD in programming languages and is a Staff Engineer at Garmin. He likes challenges; and understanding the essence of things (if there is one) constitutes the biggest challenge of all.
