








Writing efficient code is challenging but worthwhile. Andrew Drakeford demonstrates how SIMD (Single Instruction Multiple Data) can reduce your carbon footprint.
Some sources claim that data centres consumed 2.9% of the world’s electricity in 2021 [Andrae15]. With the recent sharp increase in energy prices, many firms became aware of this cost. Additionally, trends in AI use and the near-exponential growth in both network and data services projected over the next few years [Jones18] suggest that this situation will only get worse.
A data centre’s single purpose is to run our software (not heat the planet). But what if the processing cores that our software runs on have a unique, often unused, feature that would enable them to do the work several times faster? Would this also mean several times more efficiently? This feature is SIMD (Single Instruction Multiple Data).
SIMD is a parallel computing technology that allows processors to perform the same operation on multiple data elements simultaneously. By using SIMD instructions, a single CPU instruction can operate on multiple data elements in a single clock cycle. For example, with 256-bit SIMD registers, it is possible to process eight 32-bit floating-point numbers or sixteen 16-bit integers in parallel. This leverages the data-level parallelism inherent in many algorithms, such as mathematical computations, image processing, audio processing, and simulations. Figure 1 illustrates the element-wise addition of two sets of numbers using the SSE2, AVX2 and AVX512 instruction sets.
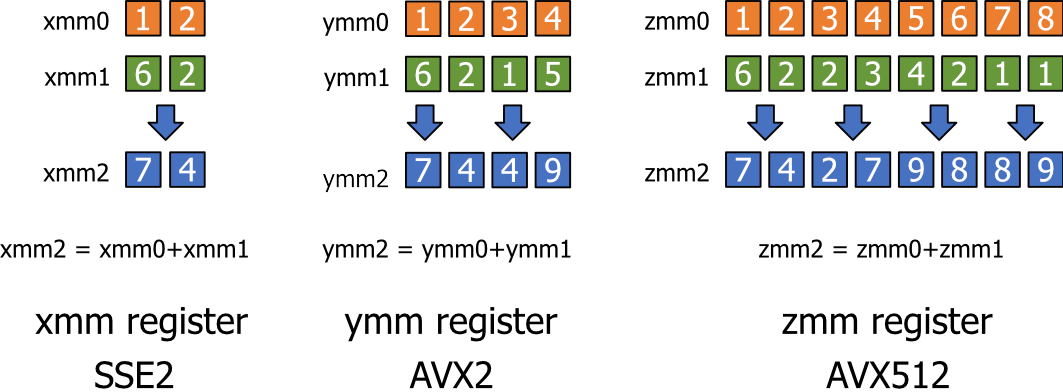 |
| Figure 1 |
SIMD instructions use vector registers, which can hold multiple data elements. These registers allow the CPU to apply a single instruction to all the elements simultaneously, thus reducing the instruction count. Consequently, SIMD can provide a substantial speedup for tasks that exhibit regular and parallelizable data processing patterns.
The experiment
To determine if utilizing SIMD instructions can save energy, we performed a straightforward experiment on widely used x86 hardware. In this experiment, we developed implementations for a standard task using three different instruction sets: SSE2, AVX2, and AVX512. Our goal was to measure power consumption while running these implementations.
Experiment setup
We created a simple application called dancingAVX512 for this purpose. This application cycles through each of the different SIMD implementations, with each one processing the workload in three bursts, separated by pauses. These pauses allow us to establish both baseline energy usage and the energy consumed during actual workload. The application runs continuously and is pinned to a single processor core. We monitor various core parameters, such as clock frequency, temperature, loading, and power consumption, using Open Hardware Monitor [OHM]. Additionally, we run a reference implementation of the same task using the C++ Standard Template Library.
Task selection
For our experiment, we chose the task of finding the maximum element in a vector of doubles. This task applies a reduction operation to a contiguous block of memory. Linearly traversing contiguous memory is highly predictable for hardware and allows efficient loading of data into vectorized registers. Moreover, reduction operations typically yield a scalar result, minimizing output size and memory writes. Additionally, we keep the vector size relatively small, it ranges from a few hundred to a few thousand doubles. This ensures that most of the processing occurs using data held in the fast L1 and L2 caches, reducing the chances of memory-related bottlenecks. These considerations are crucial to accentuating processing speed.
Implementation details
To implement the task, we leveraged the DR3 framework [DR3]. The driver code for this implementation is shown in Listing 1. It defines a generic lambda function for the task, maxDbl. maxDbl simply calls the iff function which returns the results of an element wise selection from lhs or rhs, based on the results of the comparison operator.
// The following lines determine which SIMD // namespace is in use. Uncomment the desired // namespace for the SIMD instruction set you // wish to use. //using namespace DRC::VecD8D; // avx512 // - Enables 512-bit wide vector operations. //using namespace DRC::VecD4D; // avx2 - Enables // 256-bit wide vector operations. using namespace DRC::VecD2D; // sse2 - Enables // 128-bit wide vector operations. // A volatile double is used to store the result. // Declaring it as 'volatile' prevents the // compiler from optimizing it away. volatile double res = 0.0; // A lambda function 'mxDbl' is defined to return // the maximum of two values. // The 'iff' function selects between 'lhs' or // 'rhs' based on the comparison. auto maxDbl = [](auto lhs, auto rhs) { return iff(lhs > rhs, lhs, rhs); }; // Generate a shuffled vector of size 'SZ' // starting from value '0'. auto v1 = getRandomShuffledVector(SZ, 0); // Create a SIMD vector 'vec' with the values // from 'v1'. VecXX vec(v1); // Loop 'TEST_LOOP_SZ' times, reducing the vector // 'vec' using the 'mxDbl' function and storing // the result in 'res'. for (long l = 0; l < TEST_LOOP_SZ; l++) { res = reduce(vec, maxDbl); } |
| Listing 1 |
The test loop corresponds to the experiment’s main workload. Inside the main loop, DR3::reduce applies the maxDbl algorithm over the vector of doubles, vec. Internally, DR3::reduce’s inner loop is unrolled four times to achieve better performance.
Different, instruction set specific, versions of the workload for SSE2, AVX2, and AVX512 are created just by changing the enclosing namespace. This changes the SIMD wrappers (and instruction sets) used to instantiate the generic lambda and reduction algorithm. The code is compiled with both the Intel and Clang compilers to build two versions of the test executable dancingAVX512.
Disassembly
Clang compilation
When examining the compiled code, we observe that it produces highly efficient and compact assembly code, precisely what our experiment requires. In Listing 2, we present the disassembly for the inner loops of both AVX2 and AVX512 workloads compiled using the Clang compiler.
| AVX2 |
1. vmovapd ymm4,ymmword ptr [rdx+rbx*8] 2. vmovapd ymm5,ymmword ptr [rdx+rbx*8+20h] 3. vmovapd ymm16,ymmword ptr [rdx+rbx*8+40h] 4. vmovapd ymm17,ymmword ptr [rdx+rbx*8+60h] 5. vcmppd k1, ymm0,ymm4,2 6. vmovapd ymm0{k1},ymm4 7. vcmppd k1,ymm3,ymm5,2 8. vmovapd ymm3{k1},ymm5 9. vcmppd k1,ymm1,ymm16,2 10. vmovapd ymm1{k1},ymm16 11. vcmppd k1,ymm2,ymm17,2 12. vmovapd ymm2{k1},ymm17 13. add rbx,10h 14. cmp rbx,rcx 15. jle doAVXMax512Dance+0B60h |
| AVX512 |
1. vmovapd zmm4,zmmword ptr [rdx+rbx*8] 2. vmovapd zmm5,zmmword ptr [rdx+rbx*8+40h] 3. vmovapd zmm16,zmmword ptr [rdx+rbx*8+80h] 4. vmovapd zmm17,zmmword ptr [rdx+rbx*8+0C0h] 5. vcmppd k1,zmm0,zmm4,2 6. vmovapd zmm0{k1},zmm4 7. vcmppd k1,zmm3,zmm5,2 8. vmovapd zmm3{k1},zmm5 9. vcmppd k1,zmm1,zmm16,2 10. vmovapd zmm1{k1},zmm16 11. vcmppd k1,zmm2,zmm17,2 12. vmovapd zmm2{k1},zmm17 13. add rbx,20h 14. cmp rbx,rcx 15. jle doAVXMax512Dance+390h |
| Listing 2 |
Using DR3::reduce with a generic lambda function creates almost identical disassembly for the different instruction sets. In Listing 2, we can observe the assembly code generated for the inner loops of our experiment. Below is a breakdown of what is happening in the disassembly:
- The
vmovapdinstructions load values from memory into registers (ymm4,ymm5,ymm16,ymm17for AVX2, andzmm4,zmm5,zmm16,zmm17for AVX512). - The
vcmppdinstructions perform element-wise comparisons, creating a mask (k1) that represents the results of the comparison, of the running maximums with the newly loaded values. - The
vmovapdinstructions use the mask (k1) to update the running maximum values. - The loop progresses through memory locations (
rbx) and compares against the loop counter (rcx) to determine whether to continue iterating.
Intel compilation
The disassembly generated with the Intel compiler is shown in Listing 3.
| AVX2 |
1. vmaxpd ymm0,ymm0, ymmword ptr [rdx+rax*8] 2. vmaxpd ymm1,ymm1, ymmword ptr [rdx+rax*8+20h] 3. vmaxpd ymm2,ymm2, ymmword ptr [rdx+rax*8+40h] 4. vmaxpd ymm3,ymm3, ymmword ptr [rdx+rax*8+60h] 5. add rax,10h 6. cmp rax, rsi 7. jle doAVXMax512Dance+1370h |
| AVX512 |
1. vmaxpd zmm0,zmm0, zmmword ptr [rdx+rax*8] 2. vmaxpd zmm1,zmm1, zmmword ptr [rdx+rax*8+40h] 3. vmaxpd zmm2,zmm2, zmmword ptr [rdx+rax*8+80h] 4. vmaxpd zmm3,zmm3, zmmword ptr [rdx+rax*8+0C0h] 5. add rax,20h 6. cmp rax,rsi 7. jle doAVXMax512Dance+1370h |
| Listing 3 |
This has a much shorter loop and uses the vmaxpd (maximum of packed doubles) instruction. The unrolled inner loop calls four independent vmaxpd instructions. These compare and update the running maximum values (held in zmm0, zmm1, zmm2 and zmm3) with values held in adjacent areas of memory pointed to by zmmword ptrs.
The main difference between AVX2 and AVX512 disassembly is the register width, which affects the number of doubles processed per iteration. As we move from SSE2 to AVX2 and then to AVX512, the number of elements processed doubles. This increase in processing capacity could be expected to double performance when executing the instructions at the same rate.
std::max_element comparison
The disassembly of the inner loop of the std::max_element is shown in Listing 4. Even though it uses the vector xmm registers, the instruction names are suffixed by sd, for scalar double.
1. vmovsd xmm0,qword ptr [rcx] 2. vcomisd xmm0,mmword ptr [rax] 3. cmova rax,rcx 4. add rcx,8 5. cmp rcx,rbx 6. jne doAVXMax512Dance+160h |
| Listing 4 |
The registers are used like scalars and the inner loop processes the elements sequentially, with only one double value considered per iteration. By way of contrast, the previous AVX512 listing, with a similar number of instructions, processes 32 doubles per iteration, potentially leading to a significant speed difference.
Results
Figure 2 and Figure 3 show the clock speed, temperature, load, and power recorded by the Open Hardware Monitor application [OHM] when the test application, dancingAVX512, is run on an Intel Silver Xeon 4114 (with a Skylake architecture).
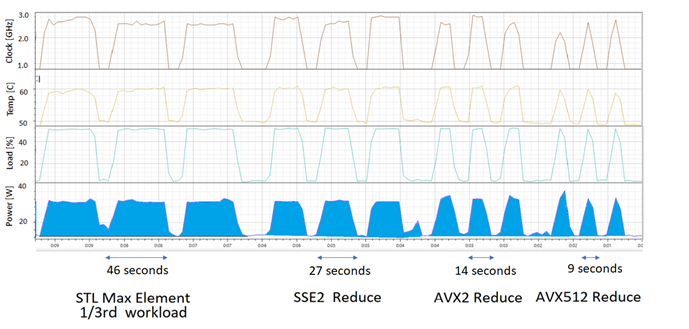 |
| Figure 2 |
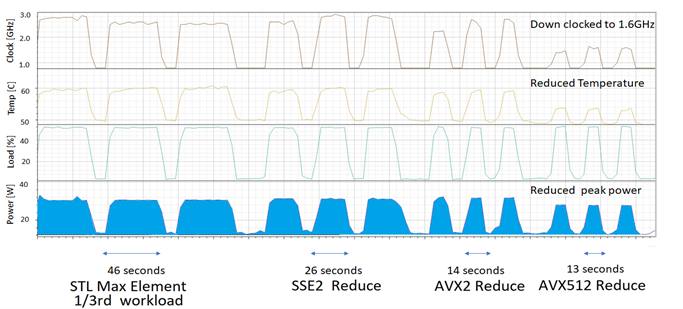 |
| Figure 3 |
The area under the power curve gives the total energy used. The area between the power curve when running a load and its background consumption level, is shaded. It corresponds to the energy used to compute the workload.
The figures show that when the workload starts, the clock frequency and temperature rise, until an equilibrium is reached. This is maintained until the task is completed. If a task runs for long enough, the run time gives a reasonable approximation of energy used when clock frequencies remain constant (and there is no reduction in power).
Figure 2 shows the power consumption for the Clang-cl build of dancingAVX512. The workload with the largest shaded area (and energy consumption) corresponds to std::max_element. For clarity, its workload is reduced to a third of that done by the other implementations. However, its energy use is nearly twice that associated with the SSE2 implementation, suggesting that it uses between five and six times more energy. The regions of the graph corresponding to executing AVX2 and AVX512 workloads show a sequential halving of runtime and energy use (indicated by the shaded area). This is what we expected from the disassembly, under the assumption that the instructions are processed at the same rate.
Figure 3 shows the power consumption of the Intel (ICC2022) build of dancingAVX512. We note that switching from AVX2 to AVX512 workloads only reduces the runtime slightly; from 14 seconds down to 13 seconds. However, the energy used (shaded area), is noticeably less. Also, with the AVX512 implementation, the temperature impulse is much smaller than with the Clang-generated code. The top plot gives the CPU clock speed and shows that for AVX512 it only boosts up to about 1.6 GHz, as compared to the 2.6 GHz for the other runs. The Intel-compiled, AVX512 task is downclocked, making it run slower than the Clang build, however, it still saves energy when compared to the AVX2 run.
Our experiment clearly shows that when software uses SIMD instructions effectively, it can make a considerable difference to power consumption.
Next steps: saving the planet
Our codebase is available on GitHub [DR3], allowing enthusiasts to replicate our experiments. While results may vary due to compiler and hardware differences, substantial improvements in performance via SIMD are evident. We hope readers are inspired to integrate SIMD instructions into their existing C++ applications. Provided that the application is not IO bound and does not have workloads that are impossible to parallelize, SIMD could make significant improvements. However, initially, some might find limited performance gains. In this situation, the most common problems are caused by:
- Memory layout: In traditional OO C++ code, typical data structures may lead to inefficient memory access patterns.
- Auto vectorization: The compilers’ auto-vectorizer does not always generate the vectorized code anticipated.
Memory layout
Memory bound, performance critical regions of legacy C++ applications often navigate diverse object collections, invoking varied virtual functions. This unpredictability in iteration leads to unpredictable memory access patterns which cause cache misses and hinder optimal CPU performance.
A SIMD speed-up will be of little use if the application’s performance is memory-bound. Refactoring is needed to remove this limitation. After an initial performance measurement step which identifies the problem areas, a two-stage refactoring process can be used to ensure the codebase is SIMD-ready. It focuses on reorganizing data to support efficient, parallel computations by enabling:
- Predictable iteration.
- Efficient SIMD invocation.
Predictable memory access is achieved by segregating the inner loop’s object collection. The original collection is divided into type-specific subsets. Iterating over and calling a member function on a group of objects of the same type, will always call the same method, so the contents of the instruction cache do not change. The subsets contain objects of the same type, which are of course, the same size. This enables us to re-organize them as an Array of Structures, (AoS). Furthermore, iterating over this layout has a very predictable memory access pattern, since the objects are all the same size. This lays down a foundation for predictable memory access.
Efficient SIMD invocation is achieved by transforming each segregated (AoS) collection into a Structure of Arrays (SoA). The array of structs of the same sub-type is converted to a new struct, where all its primitive member attributes are replaced by arrays. An individual object is represented by the collection of values found by slicing through all the member arrays at the same index. The SoA layout has the following benefits:
- Contiguity: Values of the same data attribute from multiple objects can be loaded into a SIMD register simultaneously, enhancing performance.
- Optimized cache utilization: Predictable sequential data access from the array data members in SoA means the CPU can prefetch data more effectively, reducing cache misses.
- Simplified management: In some cases, memory read by SIMD instructions needs to be aligned. Allocating memory to contain a multiple of a registers capacity and adding extra elements for padding, (if needed), simplifies processing the array. Processing padded arrays only loads a whole number of registers. Additionally, by ensuring that the first element in the padded array is aligned appropriately, all subsequent loads will satisfy the alignment requirements.
With the appropriate utilities to support transformations to SoA.[Amstutz18, Intel23] and alignment and padding, this is less arduous than one might think. A practical demonstration of vectorizing a function is given in [Drakeford22].
Refactoring with these strategies in mind not only sets the stage for effective SIMD integration, but one often sees substantial performance improvements even before SIMD comes into play. These strategies harness some of the core principles of data-oriented design [Fabian18, Straume20, Nikolov18], focusing on the properties of the typical data used by the application, and how it is accessed and processed rather than solely on its representation as a data structure.
Auto vectorization and approaches for SIMD development
Effective auto-vectorization requires loops with known sizes, simple exit conditions, and straight-line, branchless loop bodies [Bick10]. Loop-carried dependencies occur when the body of a loop reads a value computed in a previous iteration. Vectorized loops assume calculations are independent across iterations. Loop-carried dependencies break this assumption and deter the compiler from vectorizing the loop.
Sometimes, when a loop uses multiple pointers or complex pointer arithmetic, the compiler cannot be sure that the values referred to are not the same object in memory (i.e., aliasing) or an object previously written to (i.e., a loop carried dependency). It is unsafe for the compiler to generate vectorized code in such cases. However, using the compiler-specific keyword restrict with pointers, can guide the compiler. Essentially, restrict hints that the pointers are not aliases, meaning they don’t point to the same memory location. Similarly, using #pragmas with loops offers directives to the compiler, suggesting how it should process the loop. Both these techniques can encourage the compiler to generate vectorized instructions.
More invasive approaches become necessary when the compiler does not automatically vectorize the code. Various strategies and tools are available. The choice depends on the project’s specific requirements and constraints, and the available libraries and tools.
Approaches to SIMD development:
While auto-vectorization offers opportunities for optimization, manual intervention can often lead to more substantial gains. Here are some approaches to consider:
- Open MP (4): A parallel programming model for C, C++, and Fortran, which uses
#pragmas to guide compiler optimizations, though it isn’t universally supported. [Dagum98] - ISPC compiler: A performance-oriented compiler that generates SIMD code. [ISPC, Pharr12]
- Domain-specific libraries: These are libraries tailored and optimized for particular computational tasks, providing specialized functions and routines for enhanced performance.
- Intel’s MKL: Optimized math routines for science, engineering, and financial applications. [MKL]
- Eigen: A high-level C++ library for linear algebra. [Guennebaud13]
- HPX: A C++ Standard Library for parallelism and concurrency. [Kaiser20]
- Compiler intrinsics: Provide a more granular, assembly-level control by directly accessing specific machine instructions, allowing for finely tuned SIMD optimizations. [Kusswurum22, Fredrikson15, Ponce19]
- SIMD wrappers: Libraries that offer higher-level, portable interfaces for SIMD operations, making SIMD code more maintainable and readable. [Kretz12, VCL2, Creel20]
- Generative functional approaches: Utilize the C++ template mechanism (including auto) to generate code that calls the appropriate SIMD instructions.
- EVE library: Is a notable example of this approach, see [Falcou21, Penuchot18, Drakeford22].
- SYCL and Intel’s One API: Frameworks designed to develop cross-platform parallel applications, ensuring code runs efficiently across various hardware architectures [Khronos21].
- Using C++ 17’s Parallel STL: Guide the compiler to use SIMD where possible by using the
std::execution::par_unseqexecution policy.
Conclusion
The scale of energy use by data centres means that it has become a significant contributor to global pollution. Our simple experiment shows that using SIMD instructions can drastically improve energy efficiency on modern hardware. If our software made more effective use of SIMD, this could help reduce pollution.
However, achieving significant efficiency gains hinges on suitable parallelization and optimal data layouts in memory. For legacy OO systems, this typically demands carefully re-engineering the context in which the vectorized instructions run. Refactoring performance-critical regions of such systems using data-oriented design principles could be a necessary first step to enable effective use of SIMD.
Before committing to any particular approach to SIMD development, always test the performance achievable with the chosen toolset, its suitability to your problem domain, and its compatibility with your target environment.
Please help your code to consume energy responsibly.
References
[Amstutz18] Jefferson Amstutz, ‘Compute More in Less Time Using C++ Simd Wrapper Libraries’, CppCon 2018, available at https://www.youtube.com/watch?v=8khWb-Bhhvs
[Andrae15] Anders Andrae and Tomas Edler (2015). ‘On Global Electricity Usage of Communication Technology: Trends to 2030’ Challenges. 6. 117-157. https://www.mdpi.com/2078-1547/6/1/117.
[Bick10] Aarat Bick ‘A Guide to Vectorisation with Intel C++ compilers’, https://www.intel.com/content/dam/develop/external/us/en/documents/31848-compilerautovectorizationguide.pdf
[Creel20] Creel (Chris), ‘Agner Fog’s VCL 2: Performance Programming using Vector Class Library’, https://www.youtube.com/watch?v=u6v_70opPsk
[Dagum98] Leonardo Dagum and Ramesh Menon, ‘OpenMP: an industry standard API for shared-memory programming’ Computational Science & Engineering, IEEE 5.1 (1998): 46-55.
[Drakeford22] Andrew Drakeford, ‘Fast C++ by using SIMD Types with Generic Lambdas and Filters’ at CppCon 2022 https://www.youtube.com/watch?v=sQvlPHuE9KY, 6 min 35 secs
[DR3] DR3 library at https://github.com/AndyD123/DR3
[Fabian18] Richard Fabian (2018) Data-oriented design: software engineering for limited resources and short schedules, Richard Fabian.
[Falcou21] Joel Falcour and Denis Yaroshevskiy, ‘SIMD in C++20: EVE of a New Era’, CppCon 2021, available at https://www.youtube.com/watch?v=WZGNCPBMInI
[Fredrikson15] Andreas Fedrikson ‘SIMD At Insomniac Games: How We Do the Shuffle’ GDC 2015, available at https://vimeo.com/848520074.
[Guennebaud13] Gaël Guennebaud (2013) ‘Eigen: A C++ linear algebra library’ Eurographics/CGLibs, available at: https://vcg.isti.cnr.it/cglibs/. See also https://en.wikipedia.org/wiki/Eigen_(C%2B%2B_library)
[Intel23] Intel SDLT SoA_AoS https://www.intel.com/content/www/us/en/docs/dpcpp-cpp-compiler/developer-guide-reference/2023-1/simd-data-layout-templates.html
[ISPC] Intel ISPC (Implicit SPMD Program Compiler): https://ispc.github.io/ispc.html
[Jones18] N. Jones ‘How to stop data centres from gobbling up the world’s electricity’ Nature 561, 163-166 (2018)
[Kaiser20] Kaiser et al., (2020). ‘HPX – The C++ Standard Library for Parallelism and Concurrency’, Journal of Open Source Software, 5(53), 2352. https://doi.org/10.21105/joss.02352
[Khronos21] SYCL 2020 specification, launched 9 February 2021, available at https://www.khronos.org/sycl/
[Kretz12] M. Kretz and V. Lindenstruth (2012) ‘Vc: A C++ library for explicit vectorization’, Software: Practice and Experience vol 42, 11
[Kusswurum22] Daniel Kusswurum (2022) Modern Parallel Programming with C++ and Assembly Language X86 SIMD Development Using AVX, AVX2, and AVX-512, APress.
[MKL] Intel(R) math kernel library. https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html
[Nikolov18] Stoyan Nikolov ‘OOP Is Dead, Long Live Data-oriented Design’, CppCon 2018
[OHM] Open Hardware Monitor: https://openhardwaremonitor.org/
[Penuchot18] Jules Penuchot, Joel Falcou and Amal Khabou (2018) ‘Modern Generative Programming for Optimizing Small Matrix-Vector Multiplication’, in HPCS 2018
[Pharr12] M. Pharr and W. R. Mark (2012) ‘ispc: A SPMD compiler for high-performance CPU programming’ 2012 Innovative Parallel Computing (InPar), San Jose, CA, USA, pp. 1-13, doi: https://pharr.org/matt/assets/ispc.pdf.
[Ponce19] Sebastian Ponce (2019) ‘Practical Vectorisation’, Thematic CERN School of Computing, available at https://cds.cern.ch/record/2773197?ln=en
[Straume20] Per-Morten Straume (2019) ‘Investigating Data-Oriented Design’, Master’s thesis in Applied Computer Science, December 2019 NTNU Gjøvik https://github.com/Per-Morten/master_project
[VCL2] Vector Class Library (version 2): https://github.com/vectorclass/version2
A Physics PhD who started developing C++ applications in the early 90s at British Telecom labs. For the last two decades, he has worked in finance developing efficient calculation libraries and trading systems in C++. His current focus is on making quant libraries more ecologically sound. He is a member of the BSI C++ panel.
